Inference Engines for LLMs & Local AI Hardware (2026 Edition)

You don’t pick an inference engine first. You pick a hardware strategy, a workload shape, and a serving model. The engine follows.
不要先选推理引擎。你先选硬件策略、工作负载形态和服务模型。引擎会跟着这些答案出现。
That is the most useful way to think about LLM inference engines.
这是理解 LLM 推理引擎最有用的方式。
Series note: This is Part 3 in my series teaching Self-hosted LLMs / Local AI.
**系列说明:**这是我关于自托管 LLM / 本地 AI 的系列第 3 部分。
-
Part 2: Memory Bandwidth for Local AI Hardware (2026 Edition).
-
第 2 部分:Memory Bandwidth for Local AI Hardware (2026 Edition)。
Those two pieces explain the hardware capacity and bandwidth math.
前两篇解释硬件容量和内存带宽的计算方式。
This one explains the software layer that turns that hardware into usable inference.
这一篇解释把硬件变成可用推理系统的软件层。
Engines
推理引擎
These tools serve different purposes / occupy different layers
这些工具服务于不同目的,也处在不同层次:
-
Local portability
-
Consumer CUDA
-
Apple unified-memory workflows
-
Quantized inference
-
Production serving
-
Distributed orchestration
-
Vendor-optimized datacenter execution
-
本地可移植性
-
消费级 CUDA
-
Apple 统一内存工作流
-
量化推理
-
生产服务
-
分布式编排
-
厂商优化的数据中心执行
A useful mental model:
一个有用的心智模型:

The inference engine is not “the model.” It is the traffic cop, memory manager, kernel dispatcher, scheduler, cache accountant, parallelism planner, API surface, and sometimes the deployment framework.
推理引擎不是“模型”本身。它是流量指挥、内存管理器、kernel 调度器、scheduler、cache accountant、并行规划器、API surface,有时也是部署框架。
The best engine matches your memory hierarchy, interconnect, quantization format, latency and throughput targets, model architecture, and operational maturity.
最合适的引擎取决于你的内存层级、互连、量化格式、延迟和吞吐目标、模型架构以及运维成熟度。
The one-page decision guide
一页决策指南

-
Laptop / edge / odd hardware → llama.cpp
-
Mac-first workflows → MLX / MLX-LM
-
Single RTX local inference → ExLlamaV2
-
2-4+ NVIDIA / CUDA GPUs → ExLlamaV3
-
General production serving → vLLM
-
Long-context / MoE / routing → SGLang
-
NVIDIA max performance → TensorRT-LLM
-
Cluster orchestration → NVIDIA Dynamo
-
笔记本 / 边缘设备 / 奇怪硬件 → llama.cpp
-
Mac 优先工作流 → MLX / MLX-LM
-
单张 RTX 本地推理 → ExLlamaV2
-
2-4 张以上 NVIDIA / CUDA GPU → ExLlamaV3
-
通用生产服务 → vLLM
-
长上下文 / MoE / 路由 → SGLang
-
NVIDIA 最高性能 → TensorRT-LLM
-
集群编排 → NVIDIA Dynamo
The rest of this guide explains why.
下面解释原因。
What an inference engine actually does
推理引擎实际做什么
An inference engine loads weights, tokenizes input, runs the forward pass, samples tokens, maintains the KV cache, and streams results. Serious engines also handle batching, scheduling, prefix caching, quantization, parallel execution, API serving, metrics, and distributed execution.
推理引擎加载权重、分词输入、运行 forward pass、采样 token、维护 KV cache,并流式返回结果。严肃的引擎还会处理 batching、scheduling、prefix caching、quantization、parallel execution、API serving、metrics 和 distributed execution。
The workload has two phases:
工作负载有两个阶段:
Prefill reads the prompt and builds the initial KV cache. It is compute-intensive.
Prefill 读取 prompt,并构建初始 KV cache。它是计算密集型阶段。
Decode generates one token at a time, repeatedly reading weights and KV cache. It is memory-bandwidth-bound. Decode speed tracks memory bandwidth more than peak compute.
Decode 一次生成一个 token,反复读取权重和 KV cache。它受内存带宽限制。Decode 速度更多跟内存带宽相关,而不是峰值算力。
That distinction explains almost everything:
这个区别几乎解释了一切:
-
Short prompt, long answer: decode dominates → memory bandwidth and batching matter.
-
Long prompt, short answer: prefill dominates → attention kernels and chunked prefill matter.
-
Many users: scheduler quality matters → continuous batching, cache paging, fairness.
-
Long context: KV cache dominates → paged attention, KV quantization, offload.
-
MoE: expert routing dominates → expert parallelism, interconnect, grouped GEMMs.
-
Multi-node: interconnect dominates → NVLink, RDMA, pipeline parallelism, disaggregation.
-
**短 prompt、长回答:**decode 占主导 → 内存带宽和 batching 很重要。
-
**长 prompt、短回答:**prefill 占主导 → attention kernels 和 chunked prefill 很重要。
-
**很多用户:**scheduler 质量很重要 → continuous batching、cache paging、公平性。
-
**长上下文:**KV cache 占主导 → paged attention、KV quantization、offload。
-
**MoE:**expert routing 占主导 → expert parallelism、interconnect、grouped GEMMs。
-
**多节点:**interconnect 占主导 → NVLink、RDMA、pipeline parallelism、disaggregation。
PagedAttention tackled KV cache fragmentation. FlashAttention used IO-aware tiling to cut HBM (High Bandwidth Memory) traffic. Speculative decoding drafts cheap tokens and verifies them in parallel. The recurring theme: inference performance is memory movement plus scheduling.
PagedAttention 解决 KV cache 碎片问题。FlashAttention 用 IO-aware tiling 减少 HBM(High Bandwidth Memory)流量。Speculative decoding 用便宜 token 起草,再并行验证。反复出现的主题是:推理性能就是内存移动加 scheduling。
The real bottlenecks
真正的瓶颈
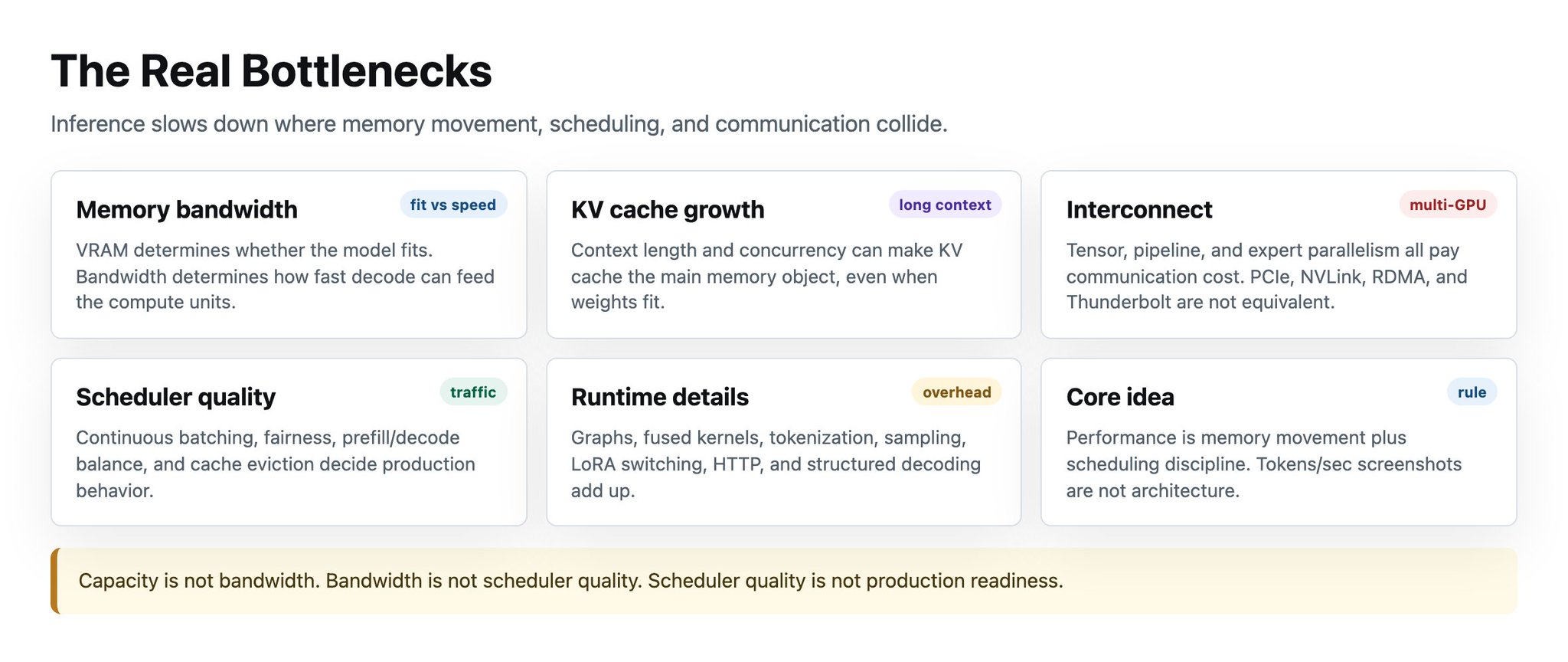
1. Memory bandwidth, not just VRAM size. VRAM determines fit. Bandwidth determines decode speed. Apple’s M3 Ultra offers up to 819 GB/s unified-memory bandwidth. NVIDIA’s H100 SXM lists 3.35 TB/s GPU memory bandwidth. Unified memory lets you fit models that would not fit in consumer VRAM. HBM lets you serve them faster when the model fits. Fit is not speed. Capacity is not bandwidth.
1. 内存带宽,不只是 VRAM 大小。VRAM 决定模型是否装得下。带宽决定 decode 速度。Apple M3 Ultra 提供最高 819 GB/s 的统一内存带宽。NVIDIA H100 SXM 标称 3.35 TB/s 的 GPU memory bandwidth。统一内存让你能装下消费者 VRAM 装不下的模型。模型装得下时,HBM 能让你服务得更快。装得下不等于快。容量不等于带宽。
2. KV cache growth. KV cache grows with batch size and context length. Long-context workloads can run out of memory even when weights fit. PagedAttention partitions the KV cache into blocks, increasing utilization and supporting larger batches.
**2. KV cache 增长。**KV cache 会随着 batch size 和 context length 增长。长上下文工作负载即使权重装得下,也可能耗尽内存。PagedAttention 把 KV cache 切分成 blocks,提高利用率并支持更大的 batches。
3. Interconnect. The moment a model crosses GPU boundaries (multi-GPUs), you pay communication cost. Tensor parallelism needs frequent all-reduce collectives. Pipeline parallelism communicates at stage boundaries. Expert parallelism needs all-to-all traffic for MoE. vLLM’s docs note that without NVLink, pipeline parallelism can outperform tensor parallelism.
**3. 互连。**模型一旦跨 GPU 边界,你就要支付通信成本。Tensor parallelism 需要频繁的 all-reduce collectives。Pipeline parallelism 在 stage 边界通信。Expert parallelism 为 MoE 产生 all-to-all 流量。vLLM 文档指出,在没有 NVLink 的情况下,pipeline parallelism 可能比 tensor parallelism 更好。
4. Scheduler quality. A good scheduler decides which requests enter the batch, how prefill and decode share the accelerator, whether long prompts block short decodes, and how to avoid starvation. Supporting batching is not the same as behaving like a production-ready scheduler.
**4. Scheduler 质量。**好的 scheduler 决定哪些请求进入 batch、prefill 和 decode 如何共享 accelerator、长 prompt 是否阻塞短 decode,以及如何避免 starvation。支持 batching 和表现得像生产级 scheduler 是两回事。
5. Runtime overhead. CUDA graphs, kernel fusion, sampling overhead, tokenizer overhead, HTTP overhead, LoRA switching, and structured decoding all matter. At high scale, the annoying 2% overheads form a union and demand attention (no punt intended).
**5. Runtime overhead。**CUDA graphs、kernel fusion、sampling overhead、tokenizer overhead、HTTP overhead、LoRA switching 和 structured decoding 都重要。在高规模下,烦人的 2% overhead 会合并起来,并需要认真关注。
The engine families
引擎家族
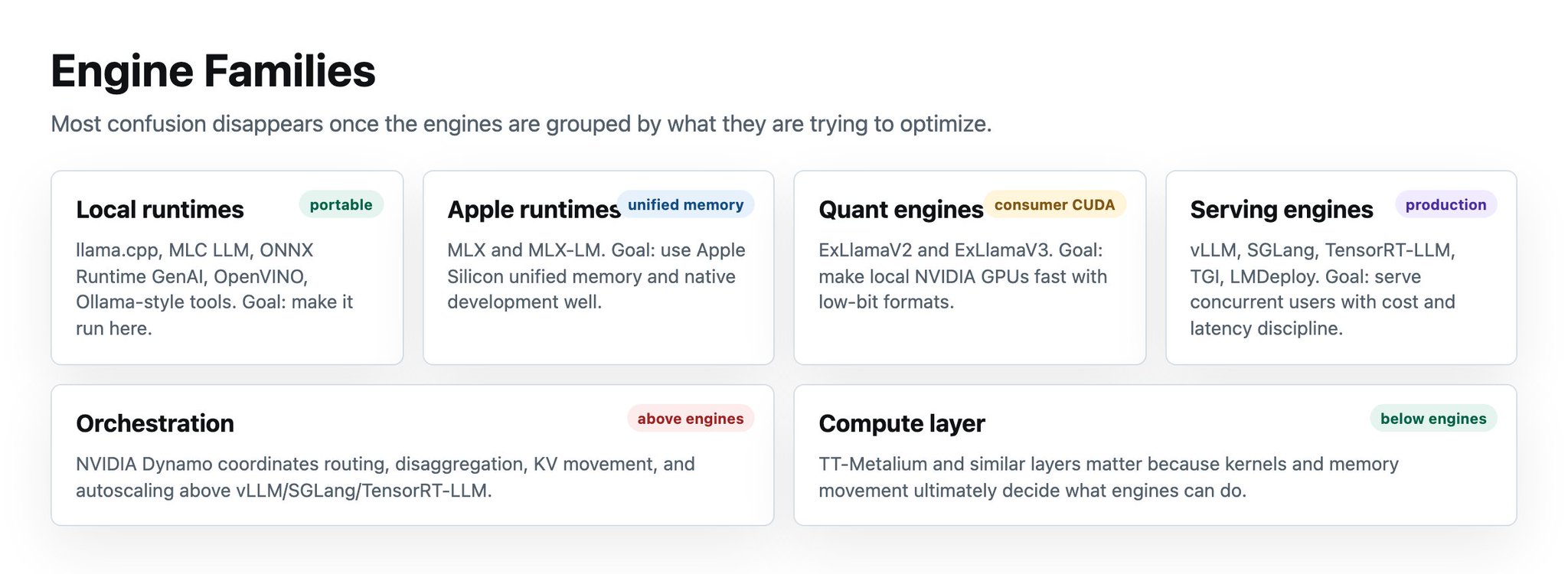
There are four broad families:
大致有四个家族:
Portable local runtimes: llama.cpp, MLC LLM, ONNX Runtime GenAI, OpenVINO, Ollama-style tools. These care about “make it run here.”
**可移植本地运行时:**llama.cpp、MLC LLM、ONNX Runtime GenAI、OpenVINO、Ollama 风格工具。它们关心的是“让它在这里跑起来”。
Apple/unified-memory runtimes: MLX and MLX-LM. These care about “use big shared memory and Apple’s stack well.”
**Apple / 统一内存运行时:**MLX 和 MLX-LM。它们关心的是“把大共享内存和 Apple stack 用好”。
Consumer CUDA quant engines: ExLlamaV2 and ExLlamaV3. These care about “make my 3090/4090/5090 box scream with low-bit weights.”
**消费级 CUDA 量化引擎:**ExLlamaV2 和 ExLlamaV3。它们关心的是“让我的 3090/4090/5090 盒子用低 bit 权重跑得很快”。
Production serving engines: vLLM, SGLang, TensorRT-LLM, TGI, LMDeploy. These care about concurrent users, KV cache, batching, parallelism, observability, and cost per token.
**生产服务引擎:**vLLM、SGLang、TensorRT-LLM、TGI、LMDeploy。它们关心并发用户、KV cache、batching、parallelism、observability 和 cost per token。
Then there are orchestration layers like Dynamo that sit above engines and coordinate fleets, disaggregated prefill/decode, routing, and autoscaling.
还有像 Dynamo 这样的编排层,位于引擎之上,协调 fleets、disaggregated prefill/decode、routing 和 autoscaling。
llama.cpp: the portability king
llama.cpp:可移植性之王
llama.cpp is the answer when the hardware is weird, constrained, offline, CPU-heavy, edge-oriented, or not a tidy NVIDIA datacenter node.
当硬件奇怪、受限、离线、CPU-heavy、偏边缘设备,或并非整齐的 NVIDIA 数据中心节点时,llama.cpp 是答案。
It supports Apple Silicon via ARM NEON, Accelerate, and Metal; x86 via AVX/AVX2/AVX512/AMX; RISC-V; low-bit quantization; CUDA; AMD via HIP; MUSA; Vulkan; SYCL; and CPU+GPU hybrid offload. That is why llama.cpp owns the “just make it run” lane.
它通过 ARM NEON、Accelerate 和 Metal 支持 Apple Silicon;通过 AVX/AVX2/AVX512/AMX 支持 x86;也支持 RISC-V、低 bit quantization、CUDA、AMD HIP、MUSA、Vulkan、SYCL,以及 CPU+GPU hybrid offload。这就是 llama.cpp 拥有“先让它跑起来”这条路径的原因。
The HTTP server is more capable than a “toy local runner”. llama-server provides OpenAI-compatible routes, Anthropic Messages API compatibility, reranking, continuous batching, multimodal support, JSON schema constraints, function calling, speculative decoding, and a web UI.
HTTP server 比“玩具本地 runner”更强。llama-server 提供 OpenAI-compatible routes、Anthropic Messages API compatibility、reranking、continuous batching、multimodal support、JSON schema constraints、function calling、speculative decoding 和 web UI。
The critical limitation: llama.cpp is not for serious multi-node production serving. Its RPC backend is explicitly documented as proof-of-concept, fragile, and insecure.
关键限制是:llama.cpp 不是严肃多节点生产服务。它的 RPC backend 明确被文档标为 proof-of-concept、fragile 和 insecure。
Verdict: Use llama.cpp when portability, offline operation, GGUF, or hybrid offload matter more than fleet-scale serving.
**结论:**当 portability、offline operation、GGUF 或 hybrid offload 比 fleet-scale serving 更重要时,用 llama.cpp。
DO NOT use with Multi-GPUs
不要用于 Multi-GPUs。
MLX and MLX-LM: the Apple Silicon weapon
MLX 和 MLX-LM:Apple Silicon 武器
MLX is Apple’s array framework for Apple Silicon, and MLX-LM is the LLM package built on it. It is a Mac-first ML stack.
MLX 是 Apple 面向 Apple Silicon 的 array framework,MLX-LM 是构建在其上的 LLM package。它是 Mac-first ML stack。
The key hardware fact is unified memory. Apple Silicon gives the CPU and GPU direct access to the same memory pool. MLX arrays live in unified memory, and you choose the device when running the operation rather than moving arrays between separate memory spaces.
关键硬件事实是统一内存。Apple Silicon 让 CPU 和 GPU 直接访问同一个内存池。MLX arrays 位于统一内存中,运行操作时选择设备,而不是在分离内存空间之间搬移 arrays。
This changes the local inference tradeoff. On a discrete GPU system, the question is “does it fit in VRAM?” On an M-series Mac with large unified memory, the question becomes “does it fit in memory, and can the memory system feed the GPU fast enough?” Large quantized models can fit on machines where the same model would be impossible on a 24 GB consumer GPU.
这改变了本地推理取舍。在离散 GPU 系统上,问题是“它能装进 VRAM 吗?”在大统一内存的 M-series Mac 上,问题变成“它能装进内存吗,以及内存系统能否足够快地喂饱 GPU?”大型量化模型可以装进一些机器,而同一个模型在 24 GB 消费级 GPU 上无法运行。
However, it is also slower.
不过,它也更慢。
MLX-LM adds Hugging Face Hub integration, quantization, LoRA and full fine-tuning, distributed inference, and a large MLX Community model ecosystem. MLX is no longer Mac-only: it offers CUDA and CPU-only packages for Linux. Distributed communication supports MPI, Ring over TCP, JACCL for RDMA over Thunderbolt, and NCCL for CUDA.
MLX-LM 增加了 Hugging Face Hub integration、quantization、LoRA 和 full fine-tuning、distributed inference,以及大型 MLX Community model ecosystem。MLX 现在已经不再只支持 Mac:它为 Linux 提供 CUDA 和 CPU-only packages。分布式通信支持 MPI、TCP ring、基于 Thunderbolt RDMA 的 JACCL,以及 CUDA 的 NCCL。
MLX-LM’s server itself warns that it is not recommended for production because it only implements basic security checks.
MLX-LM server 自己警告说,它不推荐用于生产,因为只实现了基础安全检查。
Verdict: Use MLX for Mac-first ML and LLM workflows. For high-concurrency public serving, start with a real serving stack.
**结论:**Mac-first ML 和 LLM 工作流用 MLX。高并发公开服务从真正的 serving stack 开始。
ExLlamaV2 and V3: consumer CUDA, tuned and fast
ExLlamaV2 和 V3:消费级 CUDA,调优且快速
ExLlamaV2 is the local CUDA quantization engine for people who want a consumer NVIDIA GPU to punch above its weight. It supports paged attention, dynamic batching, prompt caching, KV cache deduplication, batched generation, streaming, and speculative decoding. The word to remember is local. It makes quantized models fast on modern CUDA GPUs, especially consumer cards.
ExLlamaV2 是本地 CUDA 量化引擎,适合想让消费级 NVIDIA GPU 发挥超额能力的人。它支持 paged attention、dynamic batching、prompt caching、KV cache deduplication、batched generation、streaming 和 speculative decoding。需要记住的词是本地。它让量化模型在现代 CUDA GPU 上很快,尤其是在消费级显卡上。
Best fits: one RTX 3090/4090/5090 box, local coding assistant, local chat, EXL2 quantized models, and prosumer workstation use.
最适合:单台 RTX 3090/4090/5090 机器、本地 coding assistant、本地聊天、EXL2 量化模型和 prosumer workstation 使用。
ExLlamaV3 extends the philosophy toward multi-GPU and MoE-local inference. It adds the EXL3 quantization format based on QTIP, flexible tensor-parallel and expert-parallel inference for consumer hardware, an OpenAI-compatible server through TabbyAPI, continuous dynamic batching, and multimodal support.
ExLlamaV3 将这个思路扩展到 multi-GPU 和 MoE-local inference。它新增基于 QTIP 的 EXL3 quantization format、面向消费级硬件的 flexible tensor-parallel 和 expert-parallel inference、通过 TabbyAPI 提供的 OpenAI-compatible server、continuous dynamic batching,以及 multimodal support。
V3 is compelling when you have 2-4+ consumer NVIDIA GPUs or want local MoE. Expect caveats: some models do not support tensor or expert parallelism in ExLlamaV3.
当你有 2-4 张以上消费级 NVIDIA GPU,或想本地跑 MoE 时,V3 很有吸引力。预期会有 caveats:有些模型在 ExLlamaV3 中不支持 tensor 或 expert parallelism。
Verdict: ExLlamaV2 is the enthusiast’s local CUDA engine. ExLlamaV3 is the frontier for multi-GPU (2-4) local setups. Expect rougher edges for better capability.
**结论:**ExLlamaV2 是 enthusiast 的本地 CUDA 引擎。ExLlamaV3 是 multi-GPU(2-4 张)本地配置的前沿。你用更粗糙的边缘换取更强能力。
vLLM: the default open-source production server
vLLM:默认开源生产服务器
vLLM is the first engine most teams should evaluate for serious opensource LLM serving.
vLLM 是大多数团队在严肃开源 LLM serving 中应该首先评估的引擎。
It offers PagedAttention-based KV memory management, continuous batching, chunked prefill, prefix caching, CUDA/HIP graphs, extensive quantization (FP8, MXFP8/MXFP4, NVFP4, INT8, INT4, GPTQ, AWQ, GGUF), optimized attention and GEMM/MoE kernels, speculative decoding, torch.compile, and disaggregated prefill/decode/encode.
它提供基于 PagedAttention 的 KV memory management、continuous batching、chunked prefill、prefix caching、CUDA/HIP graphs、大量 quantization(FP8、MXFP8/MXFP4、NVFP4、INT8、INT4、GPTQ、AWQ、GGUF)、optimized attention 和 GEMM/MoE kernels、speculative decoding、torch.compile,以及 disaggregated prefill/decode/encode。
It is also flexible: tensor/pipeline/data/expert/context parallelism, streaming, structured outputs, tool calling, OpenAI-compatible and Anthropic Messages APIs, gRPC, multi-LoRA, and support for NVIDIA, AMD, x86/ARM/PowerPC CPUs, plus plugins for TPUs, Gaudi, Ascend, Apple Silicon, and more.
它也很灵活:tensor/pipeline/data/expert/context parallelism、streaming、structured outputs、tool calling、OpenAI-compatible 和 Anthropic Messages APIs、gRPC、multi-LoRA,以及对 NVIDIA、AMD、x86/ARM/PowerPC CPU 的支持,外加 TPUs、Gaudi、Ascend、Apple Silicon 等插件。
vLLM’s docs note that multi-node deployments typically use Ray, and without NVLink, pipeline parallelism may beat tensor parallelism. The trap is assuming vLLM removes the need for systems thinking. You still need to tune batching, context length, GPU memory utilization, parallelism layout, and routing. vLLM gives you a very good engine; it still requires good System Design.
vLLM 文档指出,多节点部署通常使用 Ray;没有 NVLink 时,pipeline parallelism 可能比 tensor parallelism 更好。陷阱是以为 vLLM 会移除系统思考的必要性。你仍然需要调优 batching、context length、GPU memory utilization、parallelism layout 和 routing。vLLM 给你一个很好的引擎;它仍然需要好的系统设计。
Verdict: If someone says “we need to serve open models in production,” vLLM is the default starting point.
**结论:**如果有人说“我们需要在生产中服务开放模型”,vLLM 是默认起点。
SGLang: vLLM’s systems-brained cousin
SGLang:vLLM 的系统脑亲戚
SGLang is what you reach for when the serving workload is ugly: structured outputs, long context, MoE, disaggregation, and routing.
当 serving workload 很难看时,你会用 SGLang:structured outputs、long context、MoE、disaggregation 和 routing。
It offers RadixAttention prefix caching, prefill-decode disaggregation, speculative decoding, continuous batching, paged attention, tensor/pipeline/expert/data parallelism, structured outputs, chunked prefill, and multi-LoRA batching. It supports NVIDIA, AMD, Intel Xeon, Google TPUs, Ascend NPUs, and more.
它提供 RadixAttention prefix caching、prefill-decode disaggregation、speculative decoding、continuous batching、paged attention、tensor/pipeline/expert/data parallelism、structured outputs、chunked prefill 和 multi-LoRA batching。它支持 NVIDIA、AMD、Intel Xeon、Google TPUs、Ascend NPUs 等。
SGLang’s differentiator is serving architecture. Its prefill-decode disaggregation separates compute-intensive prefill from memory-intensive decode into specialized instances, transferring KV cache between them. This prevents long prefill batches from interrupting decode and spiking token latency.
SGLang 的差异点是 serving architecture。它的 prefill-decode disaggregation 把计算密集型 prefill 和内存密集型 decode 拆到专门实例里,并在它们之间传输 KV cache。这能防止长 prefill batch 打断 decode 并抬高 token latency。
Verdict: SGLang is for teams whose bottleneck is no longer “can we run the model?” but “can we run it under hostile traffic without torching latency, memory, and cost?”
**结论:**SGLang 适合那些瓶颈已经从“能不能跑模型?”变成“能否在敌对流量下运行,同时不烧掉延迟、内存和成本?”的团队。
TensorRT-LLM: maximum NVIDIA performance
TensorRT-LLM:NVIDIA 最大性能
TensorRT-LLM is the NVIDIA-max-performance stack. It is optimized, specialized, powerful, and not pretending to be portable.
TensorRT-LLM 是 NVIDIA 最大性能 stack。它经过优化、专门化、功能强大,并且不假装自己可移植。
It provides Python APIs to build TensorRT engines with state-of-the-art optimizations, plus Python and C++ runtimes. It includes custom kernels for attention, GEMMs, and MoE; prefill-decode disaggregation, Wide Expert Parallelism, speculative decoding; and a high-level Python API integrated with NVIDIA Dynamo and Triton Inference Server.
它提供 Python APIs 用于构建带有先进优化的 TensorRT engines,也提供 Python 和 C++ runtimes。它包含 attention、GEMMs 和 MoE 的 custom kernels;prefill-decode disaggregation、Wide Expert Parallelism、speculative decoding;以及集成 NVIDIA Dynamo 和 Triton Inference Server 的 high-level Python API。
B200 GPUs can load FP4 weights with optimized kernels. H100 and later support FP8 quantization that can double performance and halve memory consumption versus 16-bit with minimal accuracy loss.
B200 GPU 可以用优化 kernels 加载 FP4 weights。H100 及后续 GPU 支持 FP8 quantization,相比 16-bit 可以在精度损失很小的情况下让性能翻倍、内存消耗减半。
Where it shines: H100/H200/B200/GB200/GB300-class fleets, NVIDIA-only datacenters, FP8/FP4 deployment, multi-node serving, and MoE at scale. Where it is awkward: AMD, Apple, or Intel portability; fast-changing experimental models; small local setups; and teams that need “works on everything.”
它擅长的地方:H100/H200/B200/GB200/GB300 级别 fleets、NVIDIA-only datacenters、FP8/FP4 deployment、multi-node serving 和大规模 MoE。它尴尬的地方:AMD、Apple 或 Intel portability;快速变化的实验模型;小型本地配置;以及需要“什么都能跑”的团队。
Verdict: If you are committed to NVIDIA and care about absolute performance, TensorRT-LLM belongs in the bake-off. You trade portability for performance. Tuned specialization but less features.
**结论:**如果你承诺使用 NVIDIA 并关心绝对性能,TensorRT-LLM 应该进入 bake-off。你用可移植性换性能。它是调优专门化,但特性面更窄。
The rest of the field
其他参与者
TGI is Hugging Face’s production server with tracing, metrics, tensor parallelism, and continuous batching. Use it when HF integration and simplicity matter.
TGI 是 Hugging Face 的生产服务器,提供 tracing、metrics、tensor parallelism 和 continuous batching。当 HF integration 和 simplicity 重要时使用。
MLC LLM is the compiler-first universal deployment engine with OpenAI-compatible APIs across REST, Python, JavaScript, iOS, and Android. Best for “ship LLMs everywhere,” especially browser, mobile, and native apps.
MLC LLM 是 compiler-first universal deployment engine,提供跨 REST、Python、JavaScript、iOS 和 Android 的 OpenAI-compatible APIs。最适合“把 LLMs 发到任何地方”,尤其是浏览器、移动端和原生应用。
ONNX Runtime GenAI implements the full generative loop over ONNX Runtime and powers Foundry Local, Windows ML, and the VS Code AI Toolkit. It supports CPU, CUDA, DirectML, TensorRT-RTX, OpenVINO, QNN, WebGPU, and AMD GPU. Best for app deployment and ONNX workflows.
ONNX Runtime GenAI 在 ONNX Runtime 上实现完整 generative loop,并支撑 Foundry Local、Windows ML 和 VS Code AI Toolkit。它支持 CPU、CUDA、DirectML、TensorRT-RTX、OpenVINO、QNN、WebGPU 和 AMD GPU。最适合 app deployment 和 ONNX workflows。
OpenVINO GenAI is the Intel-optimized story for Xeon CPUs, Arc GPUs, Core Ultra, and NPUs. It offers OpenAI-compatible serving with continuous batching and paged attention. Best for Intel hardware.
OpenVINO GenAI 是 Intel-optimized story,面向 Xeon CPU、Arc GPU、Core Ultra 和 NPU。它提供带 continuous batching 和 paged attention 的 OpenAI-compatible serving。最适合 Intel hardware。
LMDeploy is a CUDA-focused toolkit with TurboMind for performance and PyTorch for accessibility. Most interesting for CUDA users who want an alternative to vLLM/SGLang/TensorRT-LLM.
LMDeploy 是 CUDA-focused toolkit,提供偏性能的 TurboMind 和偏易用的 PyTorch。对于想要 vLLM/SGLang/TensorRT-LLM 替代品的 CUDA 用户最有意思。
NVIDIA Dynamo is a distributed orchestration layer above engines like vLLM, SGLang, and TensorRT-LLM, supporting disaggregation, intelligent routing, and multi-tier KV caching. Use it when single-engine serving is no longer enough.
NVIDIA Dynamo 是位于 vLLM、SGLang 和 TensorRT-LLM 等引擎之上的 distributed orchestration layer,支持 disaggregation、intelligent routing 和 multi-tier KV caching。当 single-engine serving 已经不够时使用。
Note: DO NOT USE Ollama.
注意:不要使用 Ollama。
Hardware strategy recipes
硬件策略配方
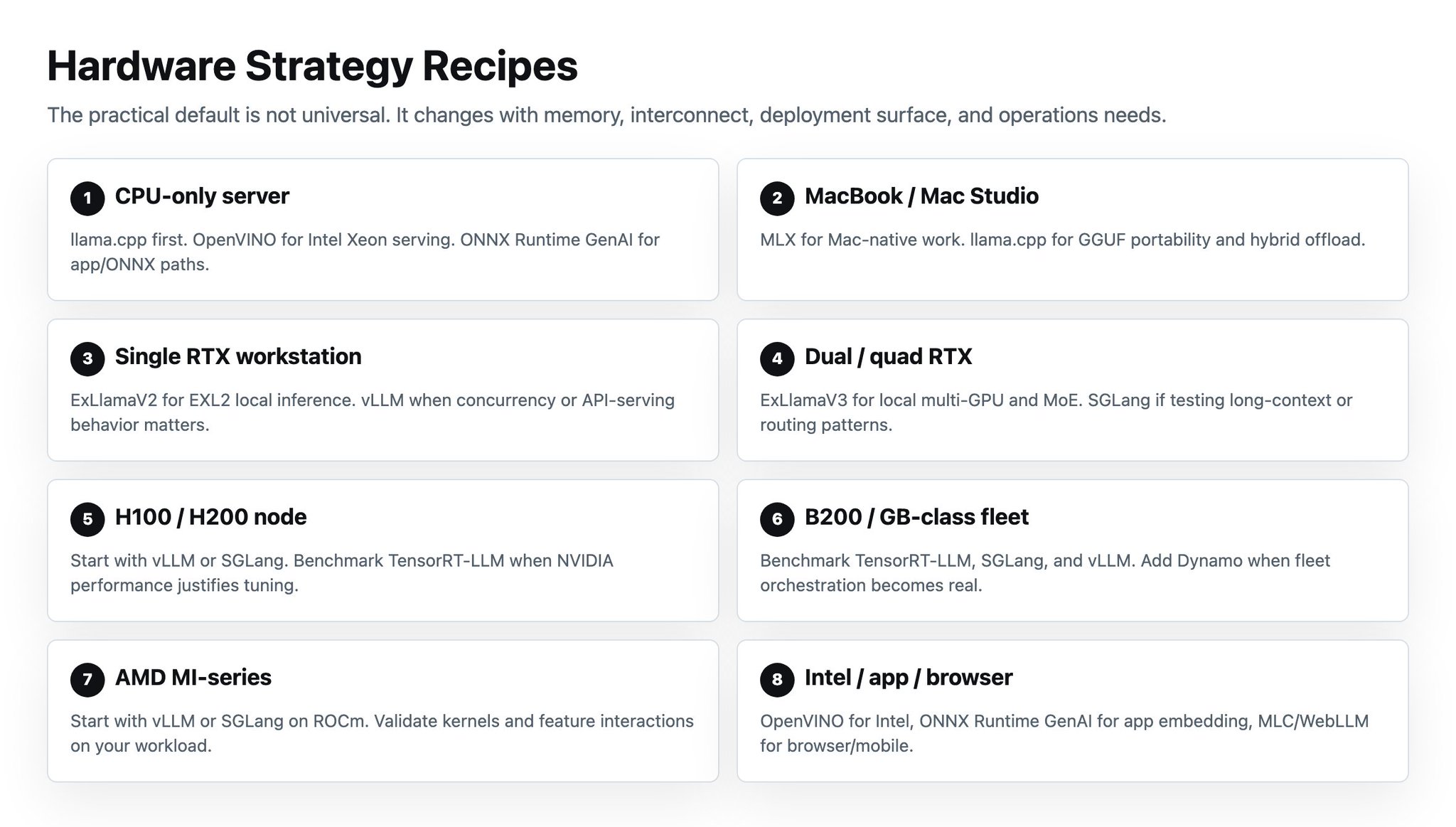
CPU-only server: llama.cpp first. OpenVINO for Intel Xeon. ONNX Runtime GenAI for app/ONNX deployment.
**CPU-only server:**优先 llama.cpp。Intel Xeon 用 OpenVINO。app/ONNX deployment 用 ONNX Runtime GenAI。
MacBook / Mac Studio: MLX / MLX-LM for Mac-native workflows. llama.cpp for GGUF portability.
**MacBook / Mac Studio:**Mac-native 工作流用 MLX / MLX-LM。GGUF portability 用 llama.cpp。
Single RTX 3090 / 4090 / 5090: ExLlamaV2 for EXL2 local inference. llama.cpp for GGUF or portability. vLLM if serving multiple users.
**单张 RTX 3090 / 4090 / 5090:**EXL2 本地推理用 ExLlamaV2。GGUF 或 portability 用 llama.cpp。如果要服务多个用户,用 vLLM。
Dual or quad consumer RTX box: ExLlamaV3 for multi-GPU quantized inference or MoE. vLLM if serving behavior matters. SGLang if testing routing or long-context patterns.
**双卡或四卡消费级 RTX 机器:**multi-GPU 量化推理或 MoE 用 ExLlamaV3。关心 serving behavior 用 vLLM。测试 routing 或 long-context patterns 用 SGLang。
8×H100 / H200 node: Start with vLLM or SGLang. Benchmark TensorRT-LLM if NVIDIA-only and performance justifies tuning. Use Dynamo when multi-node orchestration becomes necessary.
**8×H100 / H200 节点:**从 vLLM 或 SGLang 开始。如果 NVIDIA-only 且性能值得调优,benchmark TensorRT-LLM。多节点编排成为必要时使用 Dynamo。
B200 / GB200 / GB300-class infrastructure: Benchmark TensorRT-LLM, SGLang, and vLLM. Add Dynamo for fleet-level orchestration, KV-aware routing, and autoscaling.
**B200 / GB200 / GB300 级基础设施:**benchmark TensorRT-LLM、SGLang 和 vLLM。为了 fleet-level orchestration、KV-aware routing 和 autoscaling 增加 Dynamo。
AMD MI300 / MI325 / MI350 / MI355: Start with vLLM or SGLang on ROCm. Avoid assuming NVIDIA benchmarks transfer cleanly.
**AMD MI300 / MI325 / MI350 / MI355:**从 ROCm 上的 vLLM 或 SGLang 开始。避免假设 NVIDIA benchmarks 可以干净迁移。
Intel Xeon / Core Ultra / Arc: OpenVINO GenAI or OpenVINO Model Server. ONNX Runtime GenAI if app embedding matters.
**Intel Xeon / Core Ultra / Arc:**OpenVINO GenAI 或 OpenVINO Model Server。如果 app embedding 很重要,用 ONNX Runtime GenAI。
Browser, mobile, app-native: MLC LLM / WebLLM or ONNX Runtime GenAI.
**浏览器、移动端、app-native:**根据 stack 选择 MLC LLM / WebLLM 或 ONNX Runtime GenAI。
Benchmarking: what to measure
Benchmarking:应该测什么
Bad benchmark: “I got 180 tok/s.”
糟糕 benchmark:“我跑到了 180 tok/s。”
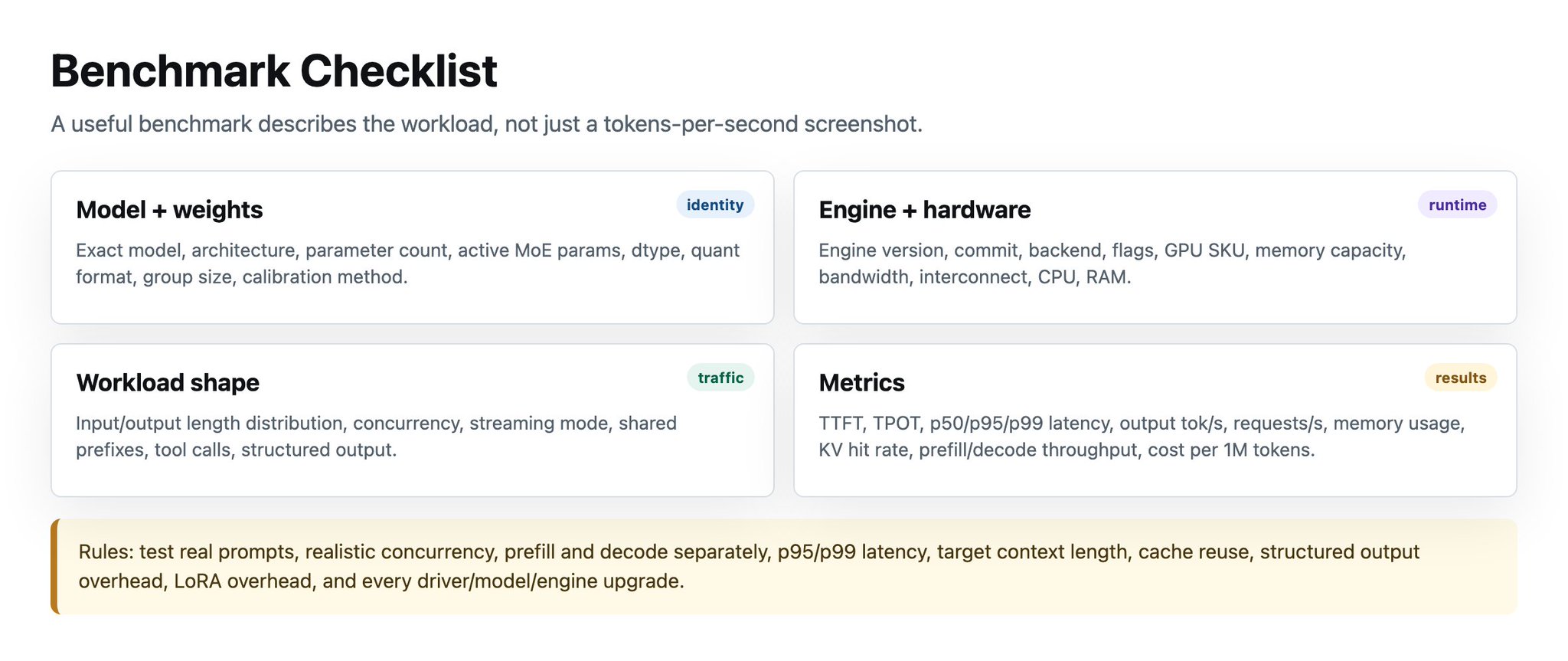
Good benchmark includes:
好的 benchmark 包含:
Model: exact model, architecture, parameter count, active MoE params.
**Model:**精确模型、架构、参数量、active MoE params。
Weights: dtype, quant format, group size, calibration.
**Weights:**dtype、quant format、group size、calibration。
Engine: version, commit, backend, flags.
**Engine:**version、commit、backend、flags。
Hardware: GPU SKU, memory capacity, bandwidth, interconnect, CPU, RAM.
**Hardware:**GPU SKU、memory capacity、bandwidth、interconnect、CPU、RAM。
Workload: input/output length distributions, concurrency, streaming, shared prefixes, structured output.
**Workload:**input/output length distributions、concurrency、streaming、shared prefixes、structured output。
Metrics: TTFT, TPOT, end-to-end latency, p50/p95/p99, tokens per second, requests per second, GPU memory usage, KV cache hit rate, prefill throughput, decode throughput, cost per 1M tokens.
**Metrics:**TTFT、TPOT、end-to-end latency、p50/p95/p99、tokens per second、requests per second、GPU memory usage、KV cache hit rate、prefill throughput、decode throughput、cost per 1M tokens。
Benchmarking Rules:
Benchmarking rules:
-
Never compare engines using only single-user tokens per second.
-
Test your actual prompt and output distribution.
-
Test with realistic concurrency.
-
Separate prefill from decode.
-
Track p95 and p99, not only averages.
-
Measure memory headroom at target context length.
-
Test cache reuse if your app has repeated prefixes.
-
Benchmark structured output separately; grammar adds overhead.
-
Benchmark LoRA and multi-LoRA separately.
-
Re-test after driver, CUDA, ROCm, model, or engine upgrades.
-
永远不要只用单用户 tokens per second 比较引擎。
-
测试你的真实 prompt 和 output distribution。
-
用现实 concurrency 测试。
-
区分 prefill 和 decode。
-
跟踪 p95 和 p99,而不只是 averages。
-
在目标 context length 下测量 memory headroom。
-
如果你的应用有重复前缀,测试 cache reuse。
-
单独 benchmark structured output;grammar 会增加 overhead。
-
单独 benchmark LoRA 和 multi-LoRA。
-
在 driver、CUDA、ROCm、model 或 engine 升级后重新测试。
Common mistakes
常见错误
Choosing by VRAM capacity alone. VRAM determines fit. Bandwidth and scheduler determine speed. A large unified-memory machine can fit huge models, but an H100 decodes faster when the model fits due to much higher HBM bandwidth.
**只按 VRAM 容量选择。**VRAM 决定是否装得下。带宽和 scheduler 决定速度。大统一内存机器能装下巨大模型,但模型装得下时,H100 因为 HBM 带宽高得多,decode 更快。
Using tensor parallelism on weak interconnect. Without NVLink or NVSwitch, test pipeline parallelism. vLLM’s docs call this out for L40S-like setups.
**在弱互连上使用 tensor parallelism。**没有 NVLink 或 NVSwitch 时,测试 pipeline parallelism。vLLM 文档对 L40S 这类设置有明确提示。
Ignoring KV cache. Long context and concurrency can make KV cache the limiting factor. PagedAttention, prefix caching, KV quantization, and disaggregation are not optional at scale.
**忽略 KV cache。**长上下文和 concurrency 可能让 KV cache 成为限制因素。PagedAttention、prefix caching、KV quantization 和 disaggregation 在 scale 下是基础能力。
Treating local engines as production servers. llama.cpp server is capable. MLX-LM server is convenient. Ollama is pleasant yet SHOULD NOT BE USED.
**把本地引擎当生产服务器。**llama.cpp server 很强。MLX-LM server 很方便。Ollama 很顺手,但不应该使用。
However, production means security, observability, backpressure, routing, autoscaling, and SLA behavior. MLX-LM itself warns that its server is not recommended for production.
不过,生产意味着 security、observability、backpressure、routing、autoscaling 和 SLA behavior。MLX-LM 自己也警告说它的 server 不推荐用于生产。
Assuming every quantization format is portable. GGUF, EXL2, EXL3, AWQ, GPTQ, FP8, FP4, MLX formats, and ONNX are not interchangeable. The right format is the one your engine has optimized kernels for.
**假设每种量化格式都可移植。**GGUF、EXL2、EXL3、AWQ、GPTQ、FP8、FP4、MLX formats 和 ONNX 不可互换。正确格式是目标引擎有 optimized kernels 的格式。
Ignoring model architecture. Dense models, MoE, hybrid attention, multimodal models, and long-context variants stress different parts of the engine. Broad support does not mean every optimization works equally.
**忽略模型架构。**Dense models、MoE、hybrid attention、multimodal models 和 long-context variants 会压迫引擎的不同部分。广泛支持不意味着每个优化都同样有效。
Trusting benchmark charts without workload shape. A chart for Llama 3.1 8B at 1K input / 128 output says little about a coding agent with 80K context running on Qwen 3.6 27B / Gemma 4 26B-A4B, or a RAG service with 500 concurrent users.
**相信没有 workload shape 的 benchmark charts。**Llama 3.1 8B 在 1K input / 128 output 下的图表,对一个在 Qwen 3.6 27B / Gemma 4 26B-A4B 上跑 80K context 的 coding agent,或一个有 500 并发用户的 RAG service,说明很少。
The opinionated final map
带观点的最终地图
Local AI user: LM Studio or Harbor for convenience. llama.cpp for control. MLX on Mac. ExLlamaV2/V3 for CUDA local performance.
**Local AI user:**为了方便用 LM Studio 或 Harbor。为了控制用 llama.cpp。Mac 上用 MLX。CUDA 本地性能用 ExLlamaV2/V3。
Building a local agent: Any should work, but given what most people use; llama.cpp for portability. MLX if users are on Apple Silicon. vLLM if simulating production serving locally.
**Building a local agent:**大多数都能用,但按常见选择:portability 用 llama.cpp。用户在 Apple Silicon 上时用 MLX。本地模拟 production serving 时用 vLLM。
Serving an internal team: Start with vLLM. Use SGLang if structured outputs, long context, multi-LoRA, MoE, or routing matter.
**Serving an internal team:**从 vLLM 开始。如果 structured outputs、long context、multi-LoRA、MoE 或 routing 重要,用 SGLang。
Serving customers at scale: Benchmark vLLM, SGLang, and TensorRT-LLM. If routing and disaggregation matter, SGLang and Dynamo deserve attention.
**Serving customers at scale:**benchmark vLLM、SGLang 和 TensorRT-LLM。如果 routing 和 disaggregation 重要,SGLang 和 Dynamo 值得关注。
NVIDIA datacenter: TensorRT-LLM for max performance. vLLM for flexibility. SGLang for complex serving. Dynamo for fleet orchestration.
**NVIDIA datacenter:**TensorRT-LLM 追求最高性能。vLLM 追求灵活性。SGLang 处理复杂 serving。Dynamo 做 fleet orchestration。
Apple Silicon: MLX for native development. llama.cpp for GGUF. Unified memory is a capacity superpower with bandwidth tradeoffs, not HBM.
**Apple Silicon:**本地开发用 MLX。GGUF 用 llama.cpp。统一内存是容量超能力,但有带宽取舍,它不是 HBM。
Edge, app, browser, or Windows-native: llama.cpp, MLC LLM, ONNX Runtime GenAI, or OpenVINO, depending on stack.
**Edge、app、browser 或 Windows-native:**根据 stack 选择 llama.cpp、MLC LLM、ONNX Runtime GenAI 或 OpenVINO。
Final principle
最终原则
Inference Engines have consequences.
推理引擎会带来后果。
Pick the engine after answering these:
在回答这些问题之后再选引擎:
-
What hardware do I actually have?
-
Does the model fit in fast memory, or only in system/unified memory?
-
Is decode or prefill the bottleneck?
-
What context length and concurrency matter?
-
Are prompts shared enough for prefix caching?
-
Is the model dense, MoE, multimodal, or hybrid?
-
Do I need local convenience, production serving, or fleet orchestration?
-
What quantization format has optimized kernels on my target engine?
-
Is my interconnect PCIe, NVLink, NVSwitch, Ethernet, RDMA, or Thunderbolt?
-
Am I optimizing latency, throughput, cost, privacy, portability, or developer speed?
-
我实际拥有什么硬件?
-
模型能装进 fast memory,还是只能装进 system/unified memory?
-
瓶颈是 decode 还是 prefill?
-
需要什么 context length 和 concurrency?
-
prompts 是否有足够共享前缀来使用 prefix caching?
-
模型是 dense、MoE、multimodal,还是 hybrid?
-
我需要 local convenience、production serving,还是 fleet orchestration?
-
目标引擎对什么 quantization format 有 optimized kernels?
-
我的 interconnect 是 PCIe、NVLink、NVSwitch、Ethernet、RDMA,还是 Thunderbolt?
-
我在优化 latency、throughput、cost、privacy、portability,还是 developer speed?
The engine follows the answers.
引擎会跟着这些答案出现。
Until next time.
下次见。
-Ahmad
-Ahmad