Context Engineering for AI Agents Lessons from Building Manus
Context Engineering for AI Agents: Lessons from Building Manus
面向 AI 智能体的上下文工程:构建 Manus 的经验教训

2025/7/18 —Yichao ‘Peak’ Ji
2025/7/18 - - 纪一超(Peak)
At the very beginning of the Manus project, my team and I faced a key decision: should we train an end-to-end agentic model using open-source foundations, or build an agent on top of the in-context learning abilities of frontier models?
在 Manus 项目刚开始时,我和团队面临一个关键抉择:是基于开源底座训练一个端到端的智能体模型,还是利用前沿模型的 上下文内学习 能力来构建智能体?
Back in my first decade in NLP, we didn’t have the luxury of that choice. In the distant days of BERT (yes, it’s been seven years), models had to be fine-tuned—and evaluated—before they could transfer to a new task. That process often took weeks per iteration, even though the models were tiny compared to today’s LLMs. For fast-moving applications, especially pre–PMF, such slow feedback loops are a deal-breaker. That was a bitter lesson from my last startup, where I trained models from scratch for open information extraction and semantic search. Then came GPT-3 and Flan-T5, and my in-house models became irrelevant overnight. Ironically, those same models marked the beginning of in-context learning—and a whole new path forward.
在我做 NLP 的头十年里,我们根本没有这种选择。回到遥远的 BERT 时代(没错,已经过去七年了),模型必须先微调、再评估,才能迁移到新任务上。即便当时的模型和今天的 LLM 相比小得多,这个过程每轮迭代往往也要几周。对于快速变化的应用,尤其是在达到 PMF 之前,这种缓慢的反馈回路是无法接受的。这是我上一家创业公司留下的惨痛教训:当时我从零开始训练模型,用于 开放信息抽取 和语义搜索。后来 GPT-3 和 Flan-T5 出现,我自研的模型一夜之间就失去了意义。讽刺的是,也正是这些模型开启了上下文内学习,以及一条全新的前进路径。
That hard-earned lesson made the choice clear: Manus would bet on context engineering. This allows us to ship improvements in hours instead of weeks, and kept our product orthogonal to the underlying models: If model progress is the rising tide, we want Manus to be the boat, not the pillar stuck to the seabed.
那次来之不易的教训让这个选择变得很明确:Manus 要押注于上下文工程。这让我们能够把改进周期从几周缩短到几小时,也让产品和底层模型保持解耦。若把模型进步看作上涨的潮水,我们希望 Manus 是船,而不是钉在海底的柱子。
Still, context engineering turned out to be anything but straightforward. It’s an experimental science—and we’ve rebuilt our agent framework four times, each time after discovering a better way to shape context. We affectionately refer to this manual process of architecture searching, prompt fiddling, and empirical guesswork as “Stochastic Graduate Descent”. It’s not elegant, but it works.
然而,上下文工程一点也不直接。它更像一门实验科学。我们已经四次重构智能体框架,每一次都是因为找到了更好的上下文塑造方式。我们戏称这种手工做架构搜索、反复调提示、靠经验猜测的过程为“随机研究生梯度下降”。它不优雅,但确实有效。
This post shares the local optima we arrived at through our own “SGD”. If you’re building your own AI agent, I hope these principles help you converge faster.
本文分享的是我们通过这套自有“SGD”流程摸索出的局部最优解。如果你也在构建自己的 AI 智能体,希望这些原则能帮你更快收敛。
Design Around the KV-Cache 围绕 KV 缓存进行设计
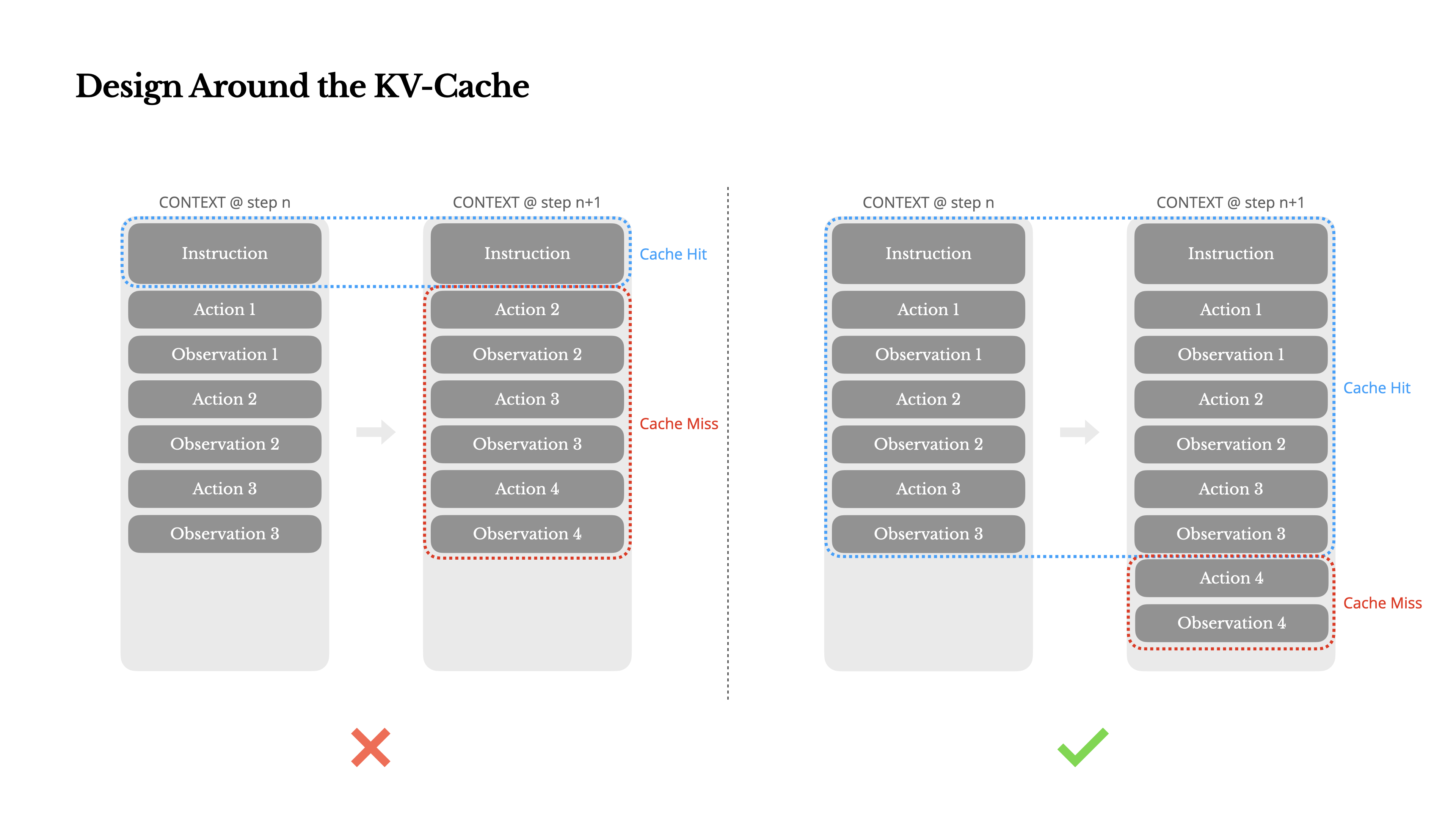
If I had to choose just one metric, I’d argue that the KV-cache hit rate is the single most important metric for a production-stage AI agent. It directly affects both latency and cost. To understand why, let’s look at how a typical agent operates:
如果只能选一个指标,我会说 KV-cache 命中率是生产环境 AI 智能体最重要的指标。它直接影响延迟和成本。要理解原因,我们先看一下 一个典型智能体 是如何工作的:
After receiving a user input, the agent proceeds through a chain of tool uses to complete the task. In each iteration, the model selects an action from a predefined action space based on the current context. That action is then executed in the environment (e.g., Manus’s virtual machine sandbox) to produce an observation. The action and observation are appended to the context, forming the input for the next iteration. This loop continues until the task is complete.
接收到用户输入后,智能体会按照一系列工具的使用步骤完成任务。在每次迭代中,模型会根据当前上下文从预定义的动作空间中选择一个动作 。然后,该动作会在环境 (例如,Manus 的虚拟机沙箱)中执行,生成一个观察结果 。该动作和观察结果会被添加到上下文中,作为下一次迭代的输入。这个循环会一直持续到任务完成。
As you can imagine, the context grows with every step, while the output—usually a structured function call—remains relatively short. This makes the ratio between prefilling and decoding highly skewed in agents compared to chatbots. In Manus, for example, the average input-to-output token ratio is around 100:1.
可以想见,上下文会随着每一步不断增长,而输出通常只是较短的结构化函数调用。和聊天机器人相比,智能体场景中的预填充与解码比例会严重失衡。例如在 Manus 里,平均输入输出词元比大约是 100:1。
Fortunately, contexts with identical prefixes can take advantage of KV-cache, which drastically reduces time-to-first-token (TTFT) and inference cost—whether you’re using a self-hosted model or calling an inference API. And we’re not talking about small savings: with Claude Sonnet, for instance, cached input tokens cost 0.30 USD/MTok, while uncached ones cost 3 USD/MTok—a 10x difference.
幸运的是,前缀相同的上下文可以利用 键值缓存(KV-cache),从而大幅降低首词元时间(TTFT)和推理成本。无论你是自托管模型还是调用推理 API,这都成立。而且节省不是小数目。以 Claude Sonnet 为例,缓存输入词元的价格是 0.30 美元/MTok,未缓存则是 3 美元/MTok,差了 10 倍。
From a context engineering perspective, improving KV-cache hit rate involves a few key practices:
从上下文工程的角度来看,提高键值缓存命中率涉及以下几个关键实践:
1.Keep your prompt prefix stable. Due to the autoregressive nature of LLMs, even a single-token difference can invalidate the cache from that token onward. A common mistake is including a timestamp—especially one precise to the second—at the beginning of the system prompt. Sure, it lets the model tell you the current time, but it also kills your cache hit rate.
保持提示前缀稳定。由于 LLM 的 自回归 特性,即便只有一个词元不同,也可能让从那个词元开始的缓存全部失效。一个常见错误是在系统提示开头放时间戳,尤其是精确到秒的时间戳。它确实能让模型知道当前时间,但也会直接打掉你的缓存命中率。
2.Make your context append-only. Avoid modifying previous actions or observations. Ensure your serialization is deterministic. Many programming languages and libraries don’t guarantee stable key ordering when serializing JSON objects, which can silently break the cache.
确保上下文仅追加。 避免修改之前的操作或观察结果。确保序列化过程是确定性的。许多编程语言和库在序列化 JSON 对象时无法保证键顺序的稳定性,这可能会悄无声息地破坏缓存。
3.Mark cache breakpoints explicitly when needed. Some model providers or inference frameworks don’t support automatic incremental prefix caching, and instead require manual insertion of cache breakpoints in the context. When assigning these, account for potential cache expiration and at minimum, ensure the breakpoint includes the end of the system prompt.
必要时显式标记缓存断点。某些模型提供商或推理框架不支持自动增量式前缀缓存,而是需要手动在上下文中插入缓存断点。设置这些断点时,要考虑缓存过期的可能性;至少要确保断点覆盖系统提示的末尾。
Additionally, if you’re self-hosting models using frameworks like vLLM, make sure prefix/prompt caching is enabled, and that you’re using techniques like session IDs to route requests consistently across distributed workers.
此外,如果你使用 vLLM 等框架自托管模型,请确保启用 prefix/prompt caching,并通过 session ID 等机制把请求稳定地路由到分布式 worker。
Mask, Don’t Remove 只屏蔽,不移除
As your agent takes on more capabilities, its action space naturally grows more complex—in plain terms, the number of tools explodes. The recent popularity of MCP only adds fuel to the fire. If you allow user-configurable tools, trust me: someone will inevitably plug hundreds of mysterious tools into your carefully curated action space. As a result, the model is more likely to select the wrong action or take an inefficient path. In short, your heavily armed agent gets dumber.
随着智能体掌握更多功能,其行动空间自然会变得更加复杂——简单来说, 工具的数量会呈爆炸式增长。最近 MCP 的流行更是火上浇油。如果你允许用户配置工具,相信我:肯定会有人把数百个来路不明的工具塞进你精心设计的行动空间里。结果就是,模型更容易选择错误的行动或走上低效的路径。简而言之,你装备精良的智能体反而会变得更笨。
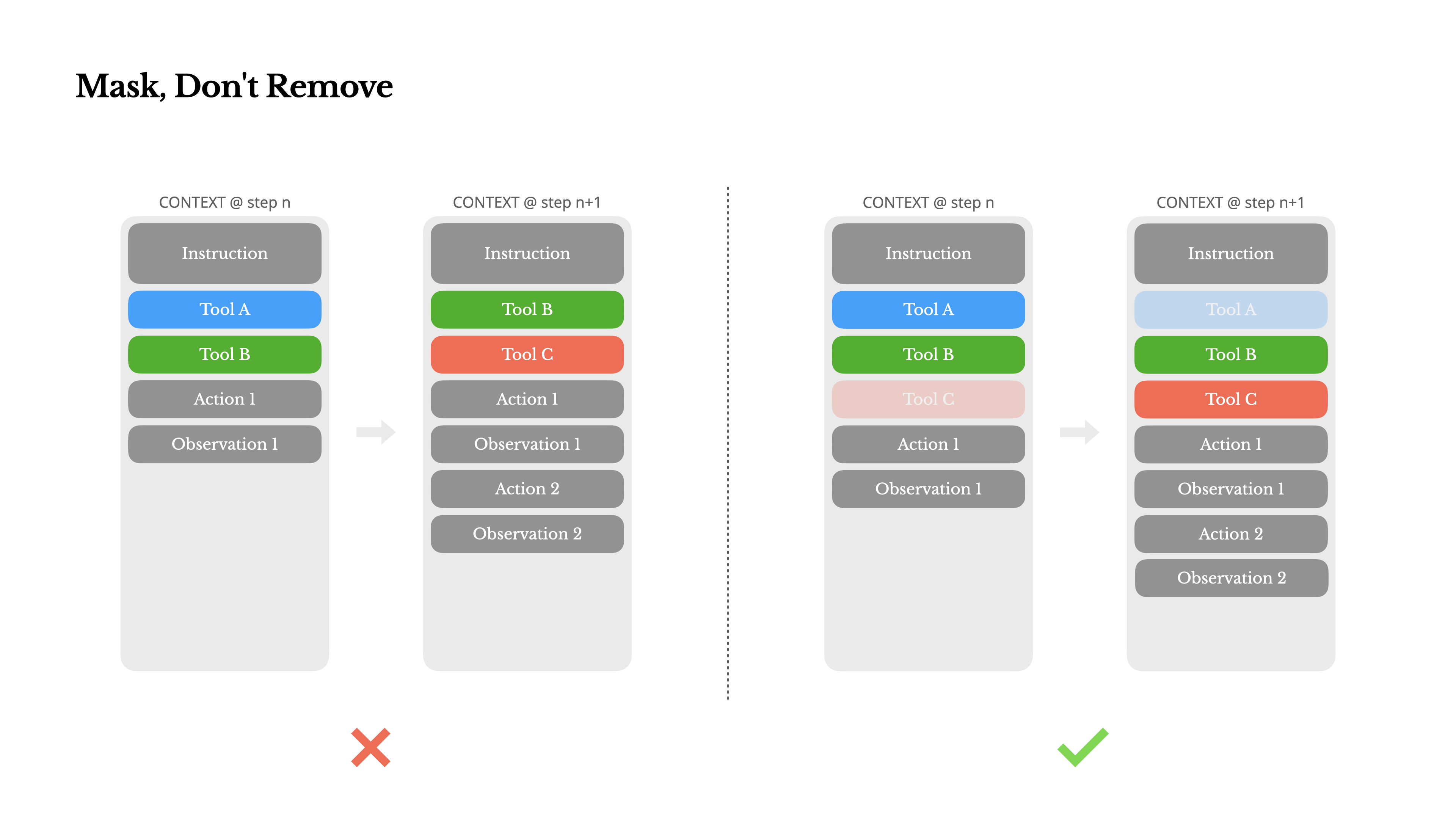
A natural reaction is to design a dynamic action space—perhaps loading tools on demand using something RAG -like. We tried that in Manus too. But our experiments suggest a clear rule: unless absolutely necessary, avoid dynamically adding or removing tools mid-iteration. There are two main reasons for this:
一个自然的反应是设计动态动作空间,比如像 RAG 一样按需加载工具。我们在 Manus 中也试过。但实验结果说明了一条明确规则:除非绝对必要,否则不要在一次迭代进行到一半时动态添加或移除工具。主要有两个原因:
1.In most LLMs, tool definitions live near the front of the context after serialization, typically before or after the system prompt. So any change will invalidate the KV-cache for all subsequent actions and observations.
在大多数 LLM 中,工具定义在序列化后都位于上下文靠前的位置,通常紧挨着系统提示之前或之后。因此,任何改动都会让后续动作和观察的 KV-cache 全部失效。
2.When previous actions and observations still refer to tools that are no longer defined in the current context, the model gets confused. Without constrained decoding, this often leads to schema violations or hallucinated actions.
当先前的动作和观察仍然引用那些在当前上下文中已经不存在定义的工具时,模型就会困惑。如果没有 约束解码,通常就会出现 schema 违例或幻觉式动作。
To solve this while still improving action selection, Manus uses a context-aware state machine to manage tool availability. Rather than removing tools, it masks the token logits during decoding to prevent (or enforce) the selection of certain actions based on the current context.
为了解决这个问题,同时提升动作选择质量,Manus 使用上下文感知的 状态机 来管理工具可用性。它不移除工具,而是在解码过程中直接屏蔽 token logits,从而根据当前上下文阻止或强制某些动作被选中。
In practice, most model providers and inference frameworks support some form of response prefill, which allows you to constrain the action space without modifying the tool definitions. There are generally three modes of function calling (we’ll use the Hermes format from NousResearch as an example):
实际上,大多数模型提供商和推理框架都支持某种形式的响应预填充,这使你可以在不修改工具定义的情况下约束动作空间。函数调用一般有三种模式(下面以 NousResearch 的 Hermes 格式 为例):
•Auto – The model may choose to call a function or not. Implemented by prefilling only the reply prefix: <|im_start|>assistant
自动 – 模型可以选择调用函数,也可以不调用。实现方式是只预填充回复前缀: <|im_start|>assistant
•Required – The model must call a function, but the choice is unconstrained. Implemented by prefilling up to tool call token: <|im_start|>assistant<tool_call>
必选 – 模型必须调用一个函数,但具体选哪个函数不受限制。实现方式是预填充到工具调用词元: <|im_start|>assistant<tool_call>
•Specified – The model must call a function from a specific subset. Implemented by prefilling up to the beginning of the function name: <|im_start|>assistant<tool_call>{“name”: “browser_
指定函数 – 模型必须从某个特定子集里调用函数。实现方式是预填充到函数名开头: <|im_start|>assistant<tool_call>{“name”: “browser_
Using this, we constrain action selection by masking token logits directly. For example, when the user provides a new input, Manus must reply immediately instead of taking an action. We’ve also deliberately designed action names with consistent prefixes—e.g., all browser-related tools start with browser_, and command-line tools with shell_. This allows us to easily enforce that the agent only chooses from a certain group of tools at a given state without using stateful logits processors.
利用这种方式,我们可以直接通过屏蔽 token logits 来约束动作选择。比如当用户刚给出新输入时,Manus 必须先回复,而不是立刻采取动作。我们还刻意把动作名设计成统一前缀,例如浏览器相关工具都以 `browser_` 开头,命令行工具都以 `shell_` 开头。这样一来,在某个状态下就能轻松限制智能体只能从某一组工具中选择,而不需要使用有状态的 logits processor。
These designs help ensure that the Manus agent loop remains stable—even under a model-driven architecture.
这些设计有助于确保 Manus 的智能体循环保持稳定,即使它采用的是模型驱动架构。
Use the File System as Context 以文件系统作为上下文
Modern frontier LLMs now offer context windows of 128K tokens or more. But in real-world agentic scenarios, that’s often not enough, and sometimes even a liability. There are three common pain points:
现代前沿大语言模型(LLM)如今已经提供 128K 甚至更大的上下文窗口。但在真实的智能体场景里,这往往仍然不够,有时甚至会成为负担。常见痛点主要有三个:
1.Observations can be huge, especially when agents interact with unstructured data like web pages or PDFs. It’s easy to blow past the context limit.
观测结果可能非常庞大,尤其是在智能体与网页或 PDF 等非结构化数据交互时,很容易冲破上下文上限。
2.Model performance tends to degrade beyond a certain context length, even if the window technically supports it.
即使上下文窗口在技术上支持,模型性能在超过某个长度后也往往会下降。
3.Long inputs are expensive, even with prefix caching. You’re still paying to transmit and prefill every token.
即使启用了前缀缓存,长输入仍然很贵。你依然要为传输和预填充每一个词元付费。
To deal with this, many agent systems implement context truncation or compression strategies. But overly aggressive compression inevitably leads to information loss. The problem is fundamental: an agent, by nature, must predict the next action based on all prior state—and you can’t reliably predict which observation might become critical ten steps later. From a logical standpoint, any irreversible compression carries risk.
为了解决这个问题,许多智能体系统都采用了上下文截断或压缩策略。但过度压缩不可避免地会导致信息丢失。问题根源在于:智能体本质上必须基于所有先前的状态来预测下一步行动——而你无法可靠地预测十步之后哪些观察结果会变得至关重要。从逻辑角度来看,任何不可逆的压缩都存在风险。
That’s why we treat the file system as the ultimate context in Manus: unlimited in size, persistent by nature, and directly operable by the agent itself. The model learns to write to and read from files on demand—using the file system not just as storage, but as structured, externalized memory.
因此,在 Manus 里,我们把文件系统视为终极上下文。它容量近乎无限,天然持久,而且可以由智能体直接操作。模型学会了按需读写文件,把文件系统不仅当作存储层,也当作结构化、外部化的记忆层。
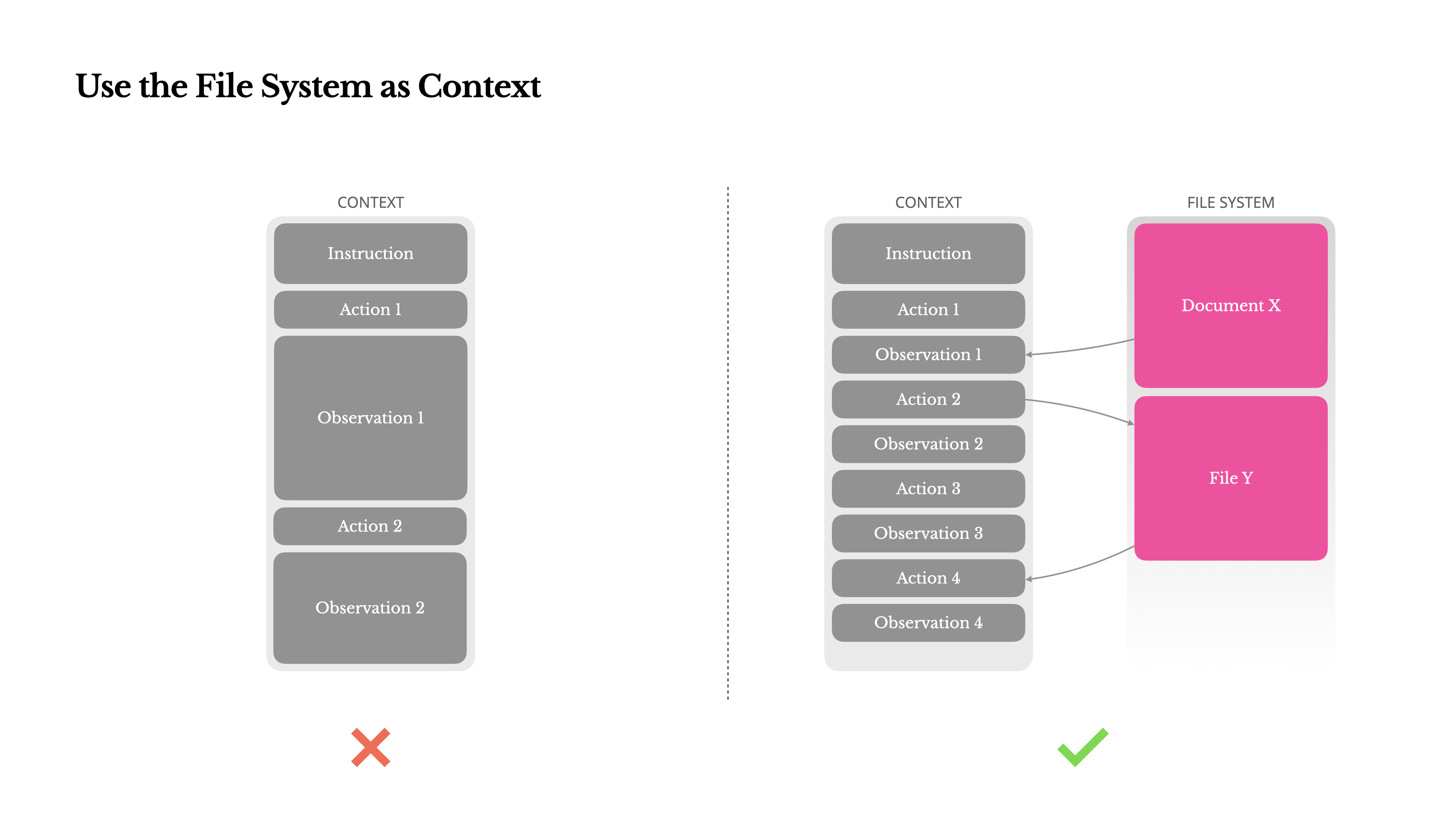
Our compression strategies are always designed to be restorable. For instance, the content of a web page can be dropped from the context as long as the URL is preserved, and a document’s contents can be omitted if its path remains available in the sandbox. This allows Manus to shrink context length without permanently losing information.
我们的压缩策略始终以“可恢复”为原则。例如,只要保留 URL,就可以把网页内容从上下文中移除;只要文档路径在沙箱中仍然可用,也可以省略文档正文。这样 Manus 就能在不永久丢失信息的前提下缩短上下文。
While developing this feature, I found myself imagining what it would take for a State Space Model (SSM) to work effectively in an agentic setting. Unlike Transformers, SSMs lack full attention and struggle with long-range backward dependencies. But if they could master file-based memory—externalizing long-term state instead of holding it in context—then their speed and efficiency might unlock a new class of agents. Agentic SSMs could be the real successors to Neural Turing Machines.
在开发这项功能时,我一直在想,状态空间模型(SSM)要怎样才能在智能体场景中真正发挥作用。与 Transformer 不同,SSM 没有完整注意力机制,也不擅长处理长距离的逆向依赖。但如果它们能掌握基于文件的记忆机制,把长期状态外部化,而不是硬塞在上下文里,那么它们的速度和效率也许会开启一类全新的智能体。Agentic SSM 可能才是 神经图灵机 真正的继承者。
Manipulate Attention Through Recitation 通过复述来操纵注意力
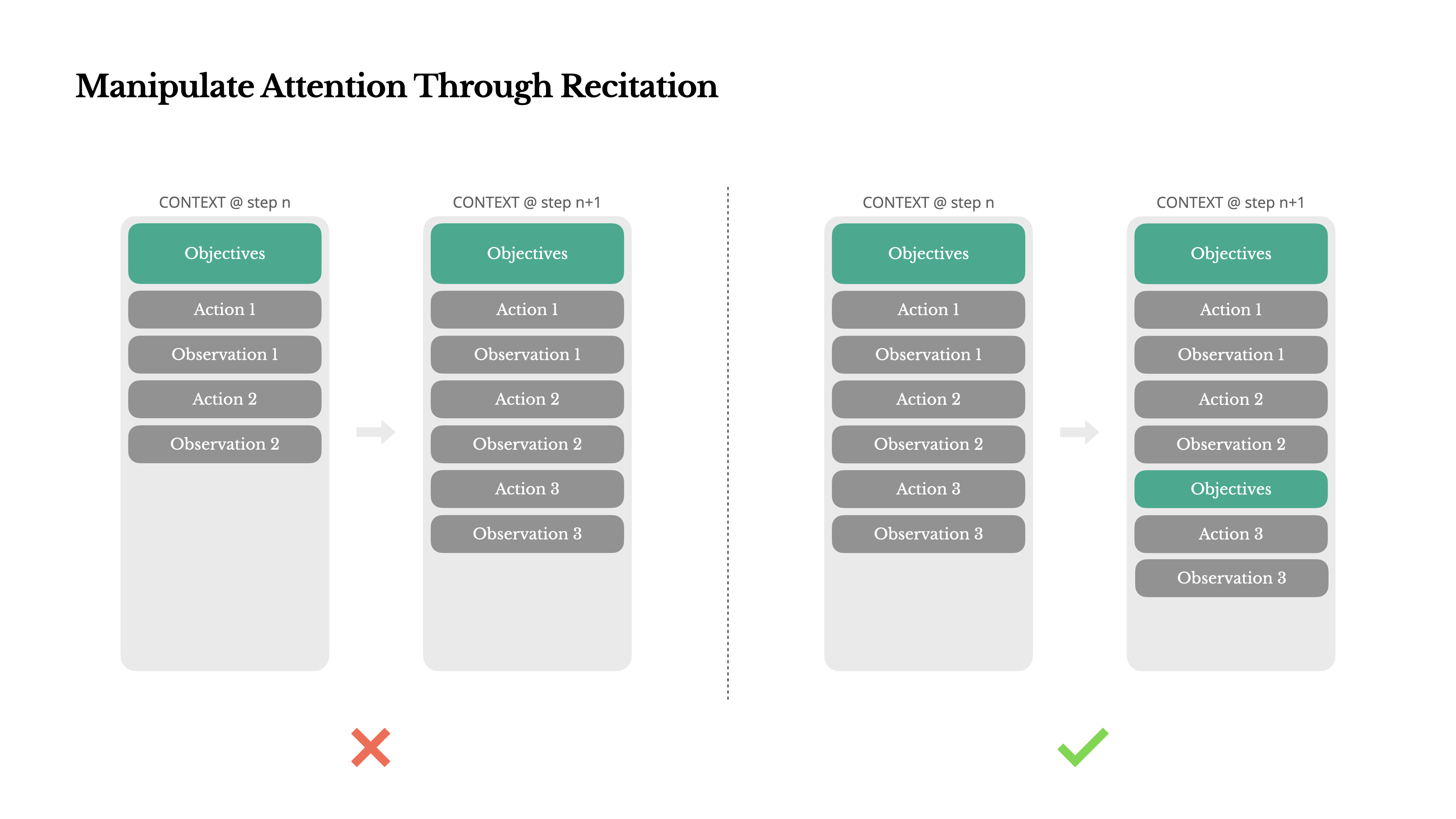
If you’ve worked with Manus, you’ve probably noticed something curious: when handling complex tasks, it tends to create a todo.md file—and update it step-by-step as the task progresses, checking off completed items.
如果你用过 Manus,你可能已经注意到一些有趣的事情:在处理复杂任务时,它倾向于创建一个 todo.md 文件,并随着任务的进行逐步更新该文件,勾选已完成的项目。
That’s not just cute behavior—it’s a deliberate mechanism to manipulate attention.
这不只是看起来可爱,而是一种有意为之的注意力操控机制。
A typical task in Manus requires around 50 tool calls on average. That’s a long loop—and since Manus relies on LLMs for decision-making, it’s vulnerable to drifting off-topic or forgetting earlier goals, especially in long contexts or complicated tasks.
在 Manus 中,一个典型任务平均大约需要 50 次工具调用。这是一个很长的循环。由于 Manus 依赖大语言模型(LLM)来做决策,它很容易在长上下文或复杂任务中跑偏,或者忘记更早设定的目标。
By constantly rewriting the todo list, Manus is reciting its objectives into the end of the context. This pushes the global plan into the model’s recent attention span, avoiding “lost-in-the-middle” issues and reducing goal misalignment. In effect, it’s using natural language to bias its own focus toward the task objective—without needing special architectural changes.
通过不断重写待办事项列表,Manus 相当于把自己的目标反复复述到上下文末尾。这会把全局计划推回模型最近的注意力范围,避免“lost in the middle”问题,并减少目标漂移。换句话说,它是在用自然语言主动把自己的注意力拉回任务目标,而不需要任何特殊架构改造。
Keep the Wrong Stuff In 把错误信息留在上下文里
Agents make mistakes. That’s not a bug—it’s reality. Language models hallucinate, environments return errors, external tools misbehave, and unexpected edge cases show up all the time. In multi-step tasks, failure is not the exception; it’s part of the loop.
智能体会犯错。这不是漏洞,而是现实。语言模型会产生幻觉,环境会返回错误,外部工具会运行异常,意想不到的极端情况也时有发生。在多步骤任务中,失败并非例外,而是循环的一部分。
And yet, a common impulse is to hide these errors: clean up the trace, retry the action, or reset the model’s state and leave it to the magical ” temperature ”. That feels safer, more controlled. But it comes at a cost: Erasing failure removes evidence. And without evidence, the model can’t adapt.
然而,一个常见冲动是把这些错误藏起来:清理痕迹、重试动作,或者重置模型状态,把一切寄托在神奇的“temperature”上。这样做看起来更安全、更可控,但代价也很明显:抹去失败,就等于抹去证据。没有证据,模型就无法调整自己的行为。

In our experience, one of the most effective ways to improve agent behavior is deceptively simple: leave the wrong turns in the context. When the model sees a failed action—and the resulting observation or stack trace—it implicitly updates its internal beliefs. This shifts its prior away from similar actions, reducing the chance of repeating the same mistake.
根据我们的经验,改进智能体行为最有效的方法之一其实很简单:把走错的路保留在上下文里。当模型看到一次失败的动作,以及由此产生的观测或堆栈追踪时,它会隐式更新自己的内部判断。这会让它对类似动作的先验倾向减弱,从而降低再次犯同样错误的概率。
事实上,我们认为错误恢复能力是衡量真正 agentic 行为最清晰的指标之一。但在大多数学术研究和公开基准里,这一点仍然被明显低估,因为它们通常只关注理想条件下的任务成功率。
Don’t Get Few-Shotted 别让少样本模式带偏
Few-shot prompting is a common technique for improving LLM outputs. But in agent systems, it can backfire in subtle ways.
少样本提示 是提升大语言模型(LLM)输出质量的常用技术。但在智能体系统中,它也可能以一些微妙的方式适得其反。
Language models are excellent mimics; they imitate the pattern of behavior in the context. If your context is full of similar past action-observation pairs, the model will tend to follow that pattern, even when it’s no longer optimal.
语言模型是优秀的模仿者;它们会模仿上下文中的行为模式 。如果你的上下文充满了类似的过往行为-观察对,即使这种模式不再是最优的,模型也倾向于遵循它。
This can be dangerous in tasks that involve repetitive decisions or actions. For example, when using Manus to help review a batch of 20 resumes, the agent often falls into a rhythm—repeating similar actions simply because that’s what it sees in the context. This leads to drift, overgeneralization, or sometimes hallucination.
在涉及重复性决策或操作的任务中,这可能会很危险。例如,当使用 Manus 来辅助审核一批 20 份简历时,智能体常常会陷入一种固定的模式——仅仅因为上下文中存在类似的操作,就重复执行相同的操作。这会导致判断偏差、过度概括,甚至有时还会出现幻觉。
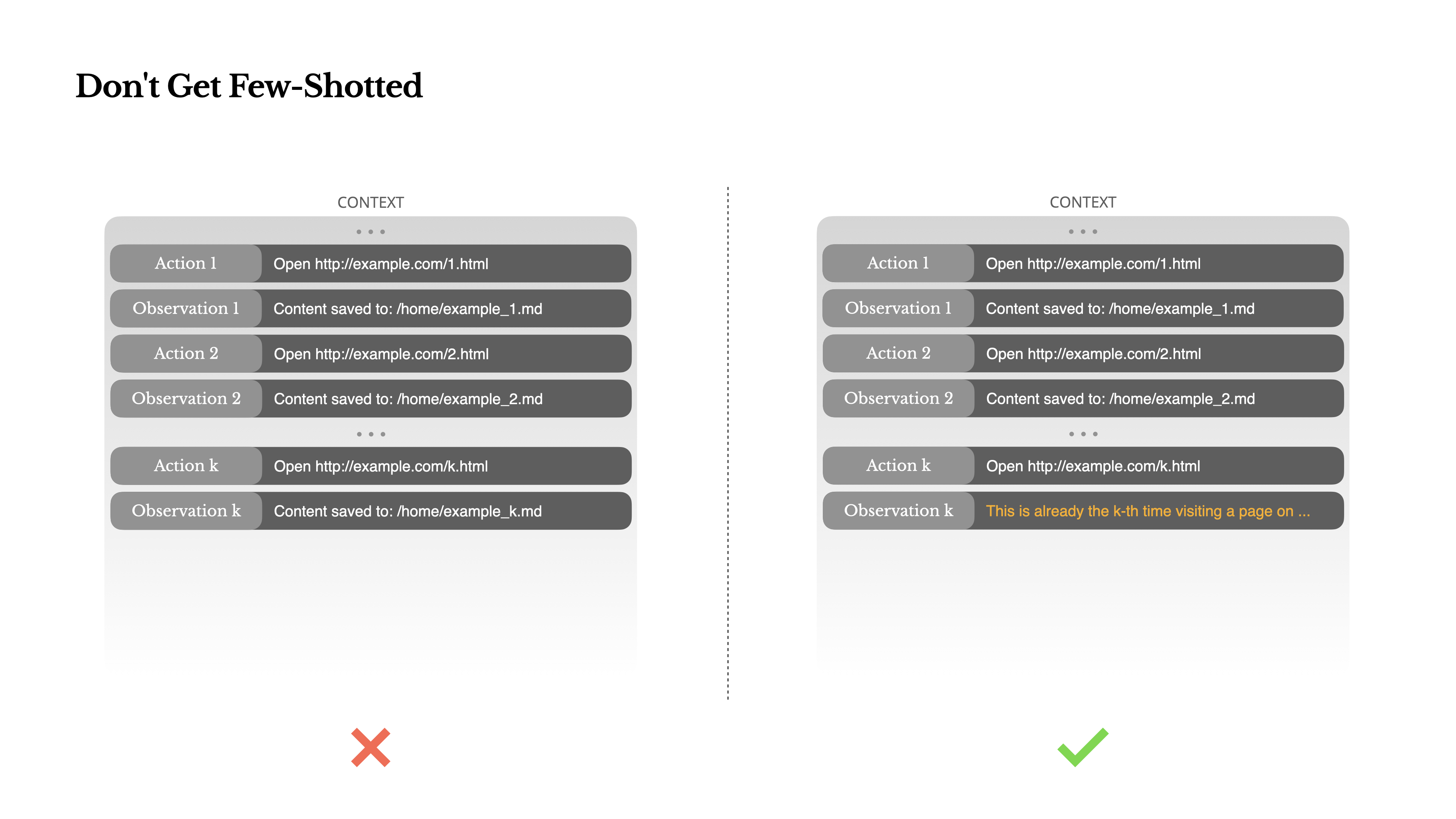
The fix is to increase diversity. Manus introduces small amounts of structured variation in actions and observations—different serialization templates, alternate phrasing, minor noise in order or formatting. This controlled randomness helps break the pattern and tweaks the model’s attention.
解决办法是增加多样性。Manus 会在动作和观察中引入少量结构化变化,例如不同的序列化模板、不同的措辞,以及顺序或格式上的轻微扰动。这种受控随机性有助于打破模式惯性,并重新调整模型的注意力。
换句话说,别把自己 few-shot 进死胡同。你的上下文越整齐划一,智能体往往就越脆弱。
Conclusion 结论
Context engineering is still an emerging science—but for agent systems, it’s already essential. Models may be getting stronger, faster, and cheaper, but no amount of raw capability replaces the need for memory, environment, and feedback. How you shape the context ultimately defines how your agent behaves: how fast it runs, how well it recovers, and how far it scales.
上下文工程仍然是一门新兴科学,但对智能体系统来说,它已经不可或缺。模型也许会越来越强、越来越快、越来越便宜,但原始能力再强,也代替不了记忆、环境和反馈。你如何塑造上下文,最终会决定智能体如何运行、如何恢复,以及能扩展到什么程度。
At Manus, we’ve learned these lessons through repeated rewrites, dead ends, and real-world testing across millions of users. None of what we’ve shared here is universal truth—but these are the patterns that worked for us. If they help you avoid even one painful iteration, then this post did its job.
在 Manus,我们通过反复重写、走弯路,以及面向数百万用户的真实世界测试,学到了这些经验。这里分享的并不是什么放之四海而皆准的真理,而只是对我们有效的模式。如果它们能帮你少经历哪怕一次痛苦的迭代,这篇文章就值了。
The agentic future will be built one context at a time. Engineer them well.
智能体的未来,是一个上下文一个上下文构建出来的。请认真设计它们。
Less structure, more intelligence.
更少结构,更多智能。
Community 社区
Compare 比较
VS ChatGPT VS Lovable 对比 Lovable