A Guide to Context Engineering for LLMs
Giving an LLM more information can make it dumber. A 2025 research study by Chroma tested 18 of the most powerful language models available, including GPT-4.1, Claude, and Gemini, and found that every single one performed worse as the amount of input grew.
给语言模型输入更多信息反而会降低它的性能。Chroma 在 2025 年进行的一项研究 测试了 18 种最强大的语言模型,包括 GPT-4.1、Claude 和 Gemini,结果发现随着输入量的增加,所有模型的性能都下降了。
The degradation wasn’t minor, either. Some models held steady at 95% accuracy and then nosedived to 60% once the input crossed a certain length.
而且性能下降幅度并不小。有些模型的准确率一开始稳定在95%,但一旦输入数据超过一定长度,准确率就会骤降至60%。
This finding busts one of the most common myths about working with LLMs that more context is always better. The reality is that LLMs have architectural blind spots that make what you put in front of them, and how you structure it, far more important than how much you include.
这一发现打破了使用 LLM 时最常见的误区之一:并不是上下文越多越好。事实上,LLM 存在架构层面的盲点,因此,你给它的信息以及你组织这些信息的方式,远比信息量本身更重要。
The discipline of getting this right is called context engineering.
把这件事做对的这门方法论,就叫上下文工程。
In this article, we’ll look at how LLMs actually process the information you give them, what context engineering is, and the strategies that can help with it.
在本文中,我们将探讨 LLM 实际如何处理你提供的信息、什么是上下文工程,以及哪些策略能帮助我们做好这件事。
Key Terminologies 关键术语
Before we go further, there are three terms that come up constantly when talking about LLMs. Getting clear on these first will make everything that follows much easier to reason about.
在深入探讨之前,先明确三个在讨论 LLM 时反复出现的术语。弄清它们之后,后面的内容会更容易理解。
- Tokens: They are the units LLMs think in. They aren’t full words, but rather chunks of text that average roughly three-quarters of a word each. The word “context” is one token, while the word “engineering” gets split into two. Every piece of text the model processes, from your question to its instructions to any documents you’ve included, is measured in tokens.
词元: 它是 LLM 处理文本的基本单位。词元不是完整的单词,而是文本片段,平均大约相当于四分之三个英文单词。“context”是一个词元,而“engineering”会被拆成两个。模型处理的所有文本,从你的问题到系统指令再到附带文档,最终都按词元计量。 - Context Window: It is the total number of tokens the model can see at once during a single interaction. Everything has to fit inside this window: the system instructions that define the model’s behavior, the conversation history, any external documents or data you’ve injected, and your actual question. Modern models advertise context windows ranging from 128,000 to over 2 million tokens. That sounds enormous, but as we’ll see, bigger isn’t straightforwardly better.
上下文窗口: 指模型在一次交互中能同时看到的词元总数。所有内容都必须放进这个窗口里,包括定义模型行为的系统指令、对话历史、注入的外部文档或数据,以及你的实际问题。现代模型宣称的上下文窗口从 12.8 万词元到 200 多万词元不等。听起来很大,但正如后文所示,窗口更大并不意味着效果一定更好。 - Attention: This is the mechanism the model uses to figure out which tokens matter to which other tokens. Before generating each new token of its response, the model compares it against every other token currently in the context window. This gives LLMs their ability to connect ideas across long stretches of text, but it’s also the source of their most important limitations.
注意力: 这是模型判断哪些词元与哪些词元相关的机制。在生成回答中的每个新词元之前,模型都会把它与当前上下文窗口中的其他词元进行比较。这让 LLM 能够跨越长文本建立联系,但也带来了它最重要的一些限制。
How LLMs Process Context 大语言模型如何处理上下文
When we send text to an LLM, it doesn’t read from top to bottom the way a human would. The attention mechanism compares every token against every other token to compute relationships, which means the model can, in principle, connect an idea from the first sentence of the input to one in the last sentence. However, this power comes with two critical costs.
当我们把文本发送给 LLM 时,它并不会像人类一样从上往下阅读。注意力机制会把每个词元与其他所有词元进行比较,从而计算它们之间的关系。这意味着理论上,模型可以把输入第一句里的概念与最后一句里的概念联系起来。但这种能力也伴随着两个关键代价。
- The first is computational. Doubling the number of tokens in the context window roughly quadruples the computation required. Longer contexts are disproportionally slower and more expensive.
首先是计算方面的问题。上下文窗口中词元数量翻倍,所需的计算量大约会增加四倍。更长的上下文处理速度会不成比例地变慢,成本也会更高。 - The second cost is more consequential. Attention isn’t distributed evenly across the context window. Research has consistently shown that LLMs pay the most attention to tokens at the beginning and end of the input, with a significant drop-off in the middle. This is known as the “lost in the middle” problem, and research has found that accuracy can drop by over 30% when relevant information is placed in the middle of the input compared to the beginning or end.
第二个代价更关键。注意力在整个上下文窗口中分布并不均匀。研究一再表明,LLM 对输入开头和结尾的词元最关注,而中间部分的关注度会明显下降。这就是所谓的“lost in the middle(中间丢失)”问题。研究发现,如果关键信息放在输入中部而不是开头或结尾,准确率可能下降 30% 以上。
See the diagram below that shows the attention curve:
请参见下图,该图显示了注意力曲线:
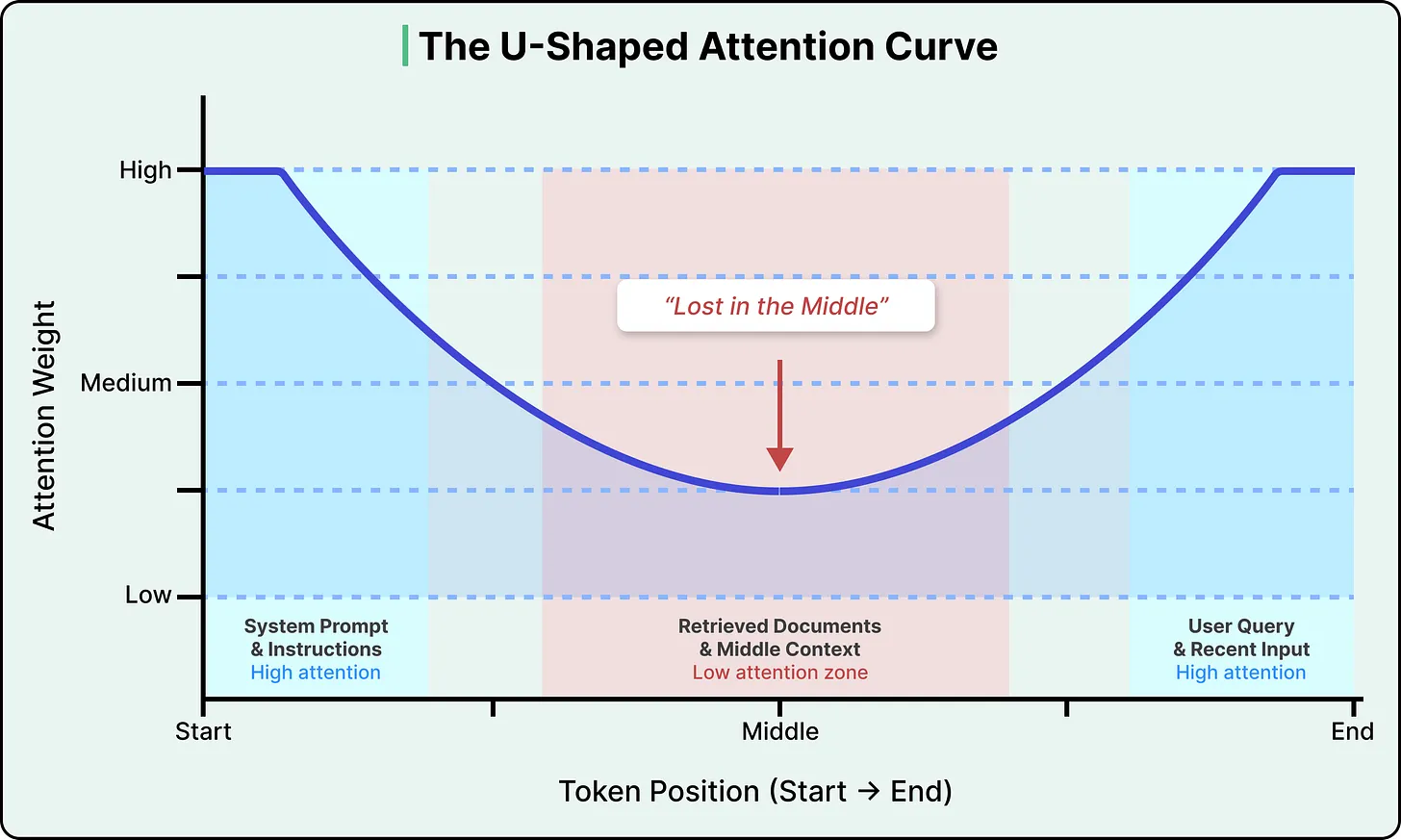
This isn’t a bug in any particular model, but rather a structural property of how transformers (the neural network architecture that powers virtually all modern LLMs) encode the position of tokens.
这不是某个特定模型的 bug,而是 Transformer 这类架构在编码词元位置时呈现出的结构性特征。几乎所有现代 LLM 都建立在这种架构之上。
The positional encoding method used in most modern LLMs (called Rotary Position Embedding, or RoPE) introduces a decay effect that makes tokens far from both the start and end of the sequence land in a low-attention zone. Newer models have reduced the severity, but no production model has fully eliminated it.
大多数现代 LLM 使用的位置编码方法叫 Rotary Position Embedding,简称 RoPE。它会带来一种衰减效应,使远离序列开头和结尾的词元落入注意力较低的区域。较新的模型已经减轻了这个问题,但还没有哪个生产级模型真正把它彻底消除。
The practical implication is that the position of information in the input matters as much as the information itself. If we paste a long document into an LLM, the model is most likely to miss information buried in the middle pages.
这在实践中的含义是,信息在输入里的位置和信息本身一样重要。如果我们把一篇很长的文档直接粘贴给 LLM,模型最容易漏掉的是埋在中间部分的信息。
Why More Context Can Hurt 为什么更多上下文反而有害
The uneven attention distribution is one problem, but there’s a broader pattern that compounds it, known as context rot.
注意力分布不均只是问题的一部分。还有一个更广泛的现象会放大它,那就是 context rot,也就是“上下文腐化”。
Context rot is the degradation of LLM performance as input length increases, even on simple tasks. The Chroma research team’s 2025 study tested 18 frontier models and found that this degradation isn’t gradual. Models can maintain near-perfect accuracy up to a certain context length, and then performance drops off a cliff unpredictably, varying by model and by task in ways that make it impossible to reliably predict when you’ll hit a breaking point.
上下文腐化指的是:随着输入变长,即使任务本身很简单,LLM 的表现也会下滑。Chroma 研究团队在 2025 年的一项研究 测试了 18 个前沿模型,发现这种退化不是平滑发生的。模型可能在某个上下文长度之前都保持接近完美的准确率,但一旦超过某个点,性能就会突然断崖式下跌,而且这个转折点会因模型和任务不同而变化,很难提前准确预测。
Why does this happen? 为什么会发生这种情况?
Every token you add to the context window draws from a finite attention budget. Irrelevant information buries important information in low-attention zones, and content that sounds related but isn’t actually useful confuses the model’s ability to identify what’s relevant. The model doesn’t get smarter with more input, but kind of gets distracted.
你添加到上下文窗口的每个词元都会占用有限的注意力资源。无关信息会将重要信息淹没在注意力较低的区域,而听起来相关但实际上无用的内容会干扰模型识别相关性。模型并不会因为输入更多而变得更聪明,反而会更容易分心。
On top of this, LLMs are stateless. They have zero memory between calls, and each interaction starts completely fresh. When there is a multi-turn conversation with an LLM like ChatGPT, and it seems to “remember” what we said earlier, that’s because the system is re-injecting the conversation history into the context window each time. The model itself remembers nothing, which means someone, or some system, has to decide for every single call what information to include, what to leave out, and how to structure it.
此外,LLM 是无状态的。它们在一次调用和下一次调用之间没有任何记忆,每次交互都是重新开始。当你和 ChatGPT 之类的 LLM 进行多轮对话时,它看起来像是“记住了”前文,实际上是系统每次都把对话历史重新注入上下文窗口。模型本身什么都不记得,这意味着每次调用都必须由人或系统来决定:该放进哪些信息、删掉哪些信息、又该如何组织这些信息。
There’s also a meaningful gap between marketing and reality. Models advertise million-token context windows, and they pass simple benchmarks at those lengths. However, the effective context length, where the model actually uses information reliably, is often much smaller. Passing a “needle in a haystack” test (finding one planted sentence in a long document) is very different from reliably synthesizing information scattered across hundreds of pages
营销宣传与实际情况之间也存在显著差距。模型宣称能够处理百万级上下文,并且确实能够通过这些长度的简单基准测试。然而,模型真正能够可靠地利用信息的有效上下文长度通常要短得多。通过“大海捞针”测试(在长篇文档中找到一个植入的句子)与可靠地综合数百页散落的信息是截然不同的两回事。
Defining Context Engineering
上下文工程的定义
Context engineering is the practice of designing, assembling, and managing the entire information environment an LLM sees before it generates a response. It goes beyond writing a single good instruction to orchestrating everything that fills the context window, so the model has exactly what it needs for the task at hand and nothing more.
上下文工程是指:在 LLM 生成回答之前,设计、组装并管理它将看到的整个信息环境。它不只是写好一条提示词,而是要编排整个上下文窗口中的所有信息,让模型在当前任务上恰好看到所需内容,不多也不少。
To understand what this involves, it helps to see what actually competes for space inside a context window. There are six types of context in a typical LLM call:
要理解这件事,一个很好的切入点是看清:上下文窗口里到底有哪些东西在争夺空间。一次典型的 LLM 调用通常包含六类上下文:
- System instructions (the behavioral rules, persona, and guidelines the model follows)
系统指令(模型遵循的行为规则、角色和准则) - User input (your actual question or command)
用户输入(您的实际问题或命令) - Conversation history (the short-term memory of the current session)
对话历史记录(当前会话的短期记忆) - Retrieved knowledge (documents, database results, or API responses pulled in from external sources)
检索到的知识(从外部来源提取的文档、数据库结果或 API 响应) - Tool descriptions (definitions of tools the model can call and how to use them)
工具描述(模型可以调用的工具的定义以及如何使用它们) - Tool outputs (results returned from previous tool calls)
工具输出(先前工具调用返回的结果) - The user’s actual question is often a tiny fraction of the total token count.
用户实际提出的问题通常只占总词数的一小部分。
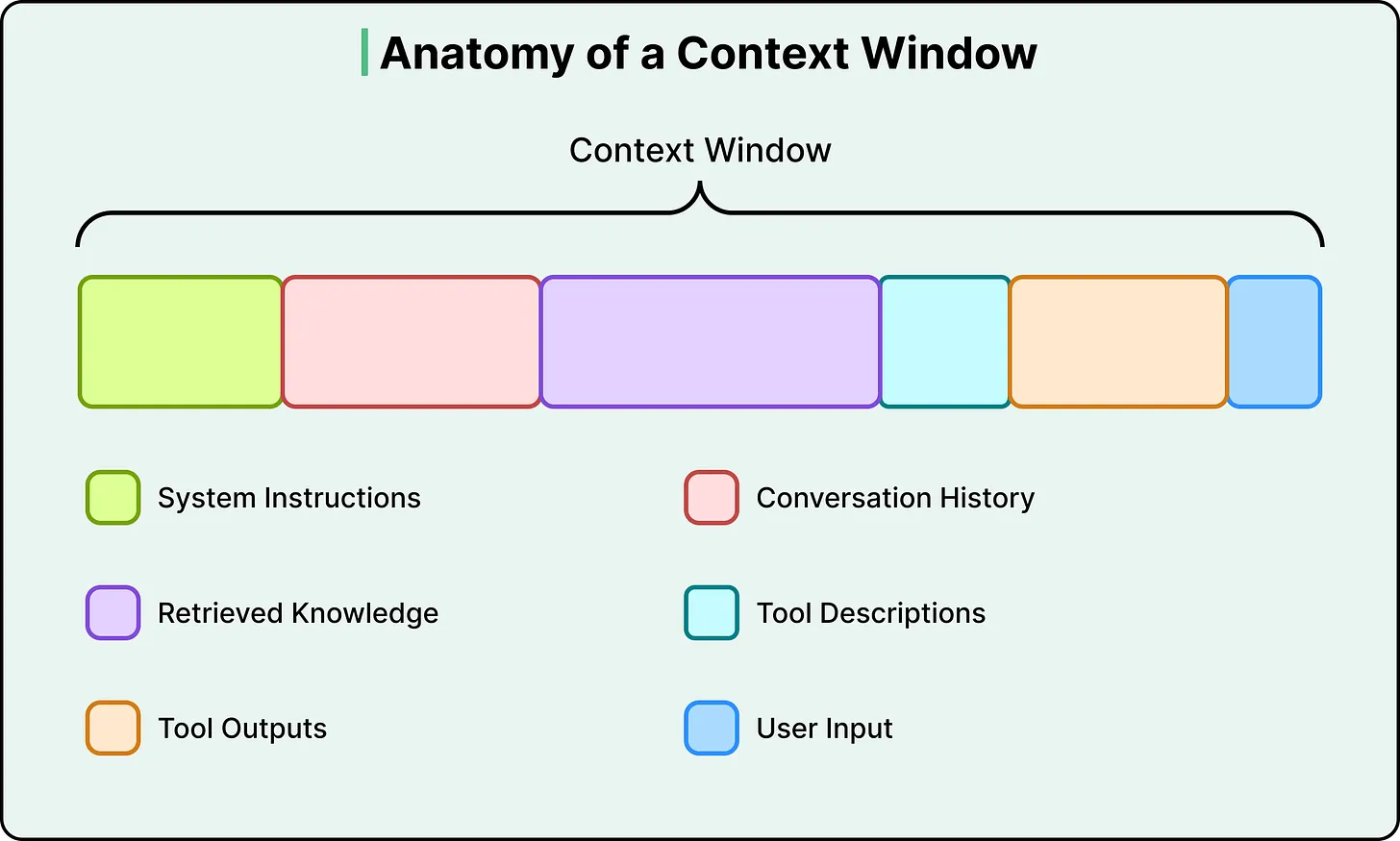
The rest is infrastructure, and that infrastructure is what context engineering designs.
其余部分都属于基础设施,而上下文工程设计的正是这套基础设施。
This also clarifies how context engineering differs from prompt engineering. Prompt engineering asks, “How do I phrase my instruction to get the best result?” On the other hand, Context engineering asks, “What does the model need to see right now, and how do I assemble all of it dynamically?”
这也阐明了上下文工程与提示工程的区别。提示工程关注的是“如何措辞才能获得最佳结果?”而上下文工程关注的是“模型现在需要看到什么,以及如何动态地整合所有这些信息?”
Prompt engineering is one component within context engineering, focused on the instruction layer, while context engineering encompasses the full information system around the model. As Andrej Karpathy put it in a widely referenced post, context engineering is the “delicate art and science of filling the context window with just the right information for the next step.”
提示工程是上下文工程的一个组成部分,侧重于指令层,而上下文工程则涵盖了围绕模型的整个信息系统。正如 Andrej Karpathy 在一篇 被广泛引用的文章 中所说 ,上下文工程是“将下一步所需的正确信息填充到上下文窗口中的精妙艺术和科学”。
Two people using the same model can get wildly different results. The model is the same, but the context is different, and context engineering is the factor that determines things.
两个人使用同一个模型,也可能得到截然不同的结果。模型没变,变的是上下文,而上下文工程正是决定结果的关键因素。
Core Strategies 核心策略
Developers have converged on four broad strategies for managing context, categorized as write, select, compress, and isolate. Each one is a direct response to a specific constraint we’ve already covered.
开发者已经逐渐收敛出四种主要的上下文管理策略,LangChain 将其概括 为 write、select、compress 和 isolate。每一种都是对前面提到的某种具体约束的直接回应。
Write: Save Context Externally
写入:把上下文保存到外部
The constraint it addresses is that the context window is finite, and statelessness means information is lost between calls.
它所解决的限制是上下文窗口是有限的,而无状态性意味着信息会在调用之间丢失。
Instead of trying to keep everything inside the context window, save important information to external storage and bring it back when needed. This takes two main forms.
与其试图把所有东西都塞进上下文窗口,不如把重要信息保存到外部存储中,在需要时再取回来。主要有两种形式。
- The first is scratchpads, where an agent saves intermediate plans, notes, or reasoning steps to external storage during a long-running task. Anthropic’s multi-agent research system does exactly this. The lead researcher agent writes its plan to external memory at the start of a task, because if the context window exceeds 200,000 tokens, it gets truncated and the plan would be lost.
第一种是 scratchpad,智能体会在长任务执行过程中把中间计划、笔记或推理步骤写到外部存储。Anthropic 的多智能体研究系统 就是这么做的。主研究员智能体会在任务开始时把计划写入外部记忆,因为一旦上下文窗口超过 20 万词元,内容就会被截断,计划也会丢失。 - The second form is long-term memory, which involves persisting information across sessions. ChatGPT auto-generates user preferences from conversations, Cursor and Windsurf learn coding patterns and project context, and Claude Code uses CLAUDE.md files as persistent instruction memory. All of these systems treat external storage as the real memory layer, with the context window serving as a temporary workspace.
第二种形式是长期记忆,它涉及跨会话持久化信息。ChatGPT 会根据对话自动生成用户偏好,Cursor 和 Windsurf 会学习编码模式和项目上下文,而 Claude Code 则使用 CLAUDE.md 文件作为持久化指令记忆。所有这些系统都将外部存储视为真正的记忆层,而上下文窗口则充当临时工作区。
Select: Pull In Only What’s Relevant
选择:只拉取相关信息
The constraint it addresses is that more context isn’t better, and the model needs the right information rather than all available information.
它所解决的限制是,更多的上下文信息并非更好,模型需要的是正确的信息,而不是所有可用的信息。
The most important technique here is Retrieval-Augmented Generation, or RAG. Instead of stuffing all your knowledge into the context window, we store it externally in a searchable database. At query time, retrieve only the chunks most relevant to the current question and inject those into the context, giving the model targeted knowledge without the noise of everything else.
这里最重要的技术是检索增强生成(Retrieval-Augmented Generation,简称 RAG)。我们并非将所有知识都塞进上下文窗口,而是将其存储在外部可搜索的数据库中。在查询时,仅检索与当前问题最相关的信息块,并将其注入上下文,从而为模型提供目标明确的知识,而不会受到其他信息的干扰。
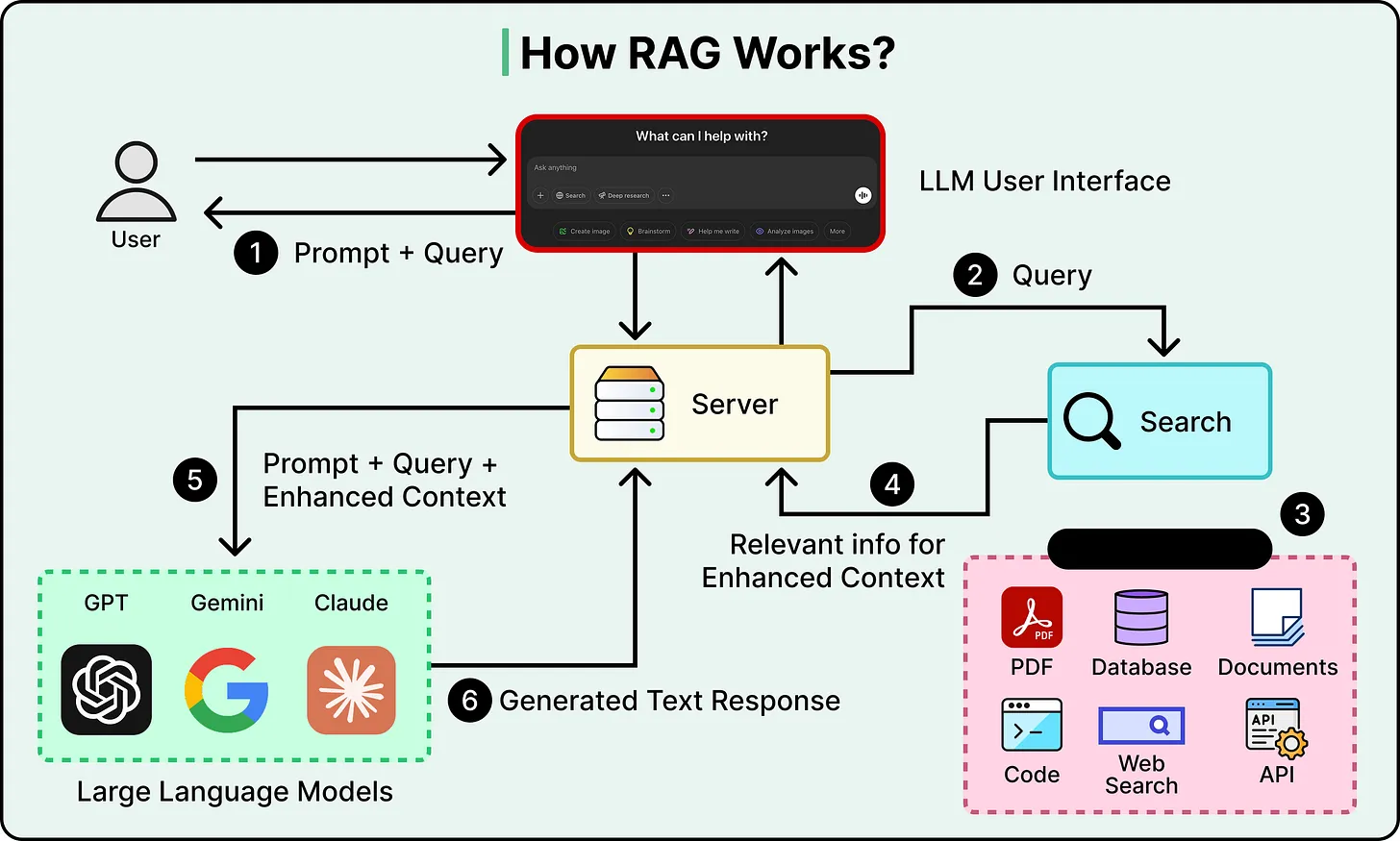
Selection also applies to tools. When an agent has dozens of available tools, listing every tool description in every prompt wastes tokens and confuses the model. A better approach is to retrieve only the tool descriptions relevant to the current task.
选择机制同样适用于工具。当智能体有几十个可用工具时,在每个提示里都列出全部工具描述既浪费词元,也会让模型困惑。更好的做法是只取回与当前任务相关的工具描述。
The critical tradeoff with selection is precision. If the retrieval pulls in documents that are almost relevant but not quite, they become distractors that add tokens and push important context into low-attention zones. The retrieval step itself has to be good, or the whole strategy backfires.
选择的关键权衡在于精确度。如果检索结果中包含一些几乎相关但又不够精确的文档,它们就会成为干扰项,增加词元数量,并将重要的上下文信息推至低关注度区域。检索步骤本身必须足够好,否则整个策略就会适得其反。
Compress: Keep Only What You Need
压缩:只保留需要的内容
The constraint it addresses is the context rot and the escalating cost of attention across more tokens.
它要解决的限制是上下文腐化,以及词元越多、注意力成本越高的问题。
As agent workflows span dozens or hundreds of steps, the context window fills up with accumulated conversation history and tool outputs. Compression strategies reduce this bulk while trying to preserve the essential information.
当智能体工作流跨越数十甚至数百步时,上下文窗口里会堆满累积的对话历史和工具输出。压缩策略的目标,就是在尽量保留关键信息的前提下削减这些体积。
Conversation summarization is the most common approach. Claude Code, for instance, triggers an “auto-compact” process when the context hits 95% capacity, summarizing the entire interaction history into a shorter form. Cognition, the company behind the Devin coding agent, trained a separate, dedicated model specifically for summarization at agent-to-agent boundaries. The fact that they built a separate model just for this step tells us how consequential bad compression can be, since a specific decision or detail that gets summarized away is gone permanently.
对话摘要是最常见的方式。例如,Claude Code 会在上下文容量达到 95% 时触发“auto-compact”流程,把整个交互历史压成更短的版本。Devin 编码智能体背后的 Cognition 甚至专门训练了一个独立模型,用来在智能体与智能体之间做摘要。他们专门为这一步单独做模型,本身就说明压缩做坏了会有多严重,因为一旦某个关键决策或细节在摘要中被抹掉,它就永久丢失了。
Simpler forms of compression include trimming (removing older messages from the history) and tool output compression (reducing verbose search results or code outputs to their essentials before they enter the context).
更简单的压缩方式还包括裁剪,也就是从历史中移除较早的消息;以及工具输出压缩,也就是在搜索结果或代码输出进入上下文之前,先把它们压缩成更精简的形式。
Isolate: Split Context Across Agents
隔离:在多个智能体之间拆分上下文
The constraint it addresses is that of attention dilution and context poisoning when too many types of information compete in one window.
它所解决的限制是,当太多类型的信息在一个窗口中相互竞争时,会导致注意力分散和上下文干扰。
Instead of one agent trying to handle everything in a single bloated context window, this strategy splits the work across multiple specialized agents, each with its own clean, focused context. A “researcher” agent gets a context loaded with search tools and retrieved documents, while a “writer” agent gets a context loaded with style guides and formatting rules, so neither is distracted by the other’s information.
这种策略并非让一个代理试图在一个臃肿的上下文窗口中处理所有事情,而是将工作分配给多个专业代理,每个代理都拥有自己清晰、专注的上下文。“研究者”代理的上下文加载了搜索工具和检索到的文档,而“撰稿人”代理的上下文加载了样式指南和格式规则,这样双方都不会受到对方信息的干扰。
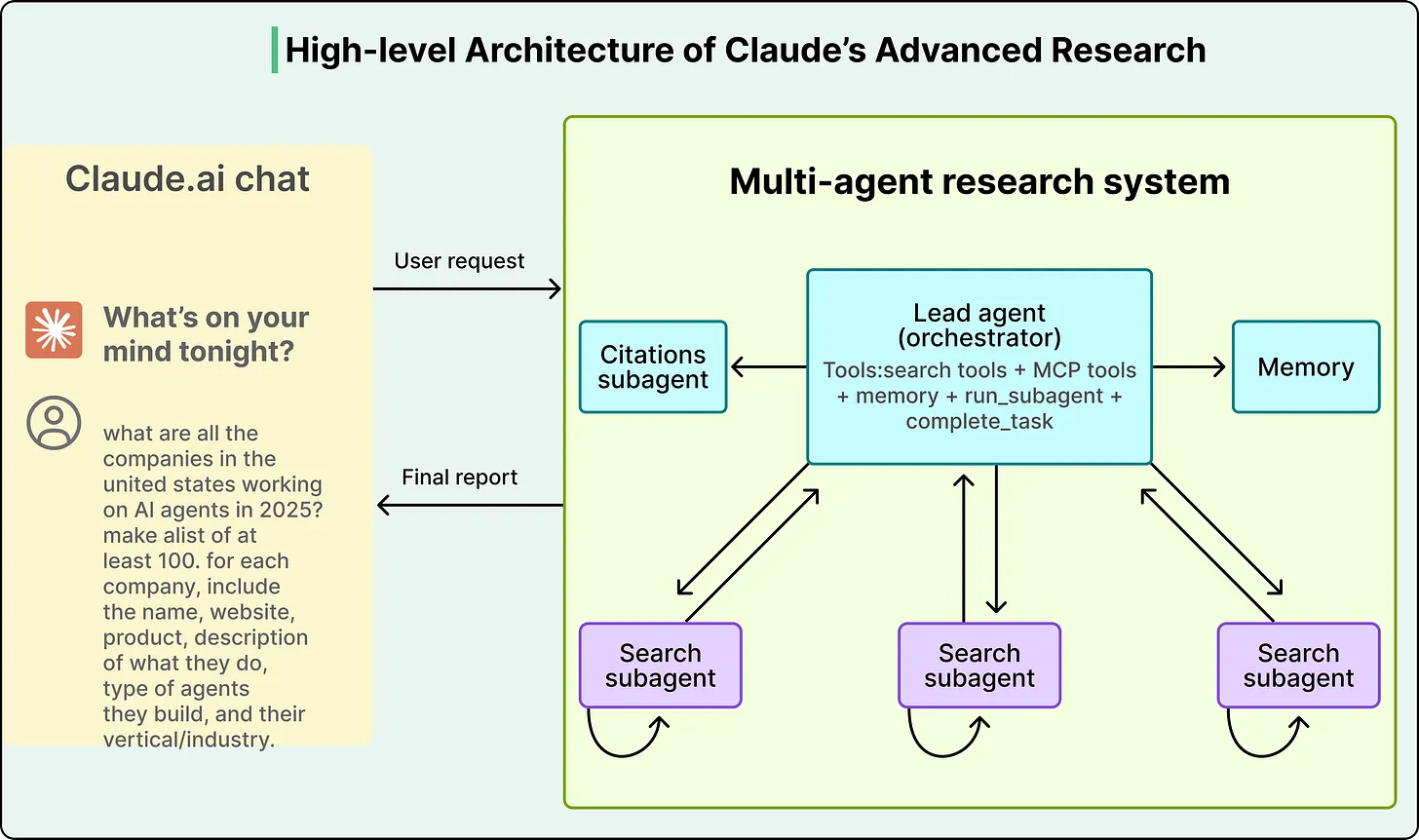
Anthropic demonstrated this with their multi-agent research system, where a lead Opus 4 agent delegated sub-tasks to Sonnet 4 sub-agents. The system achieved a 90.2% improvement over a single Opus 4 agent on research tasks, despite using the same underlying model family. The entire performance gain came from how context was managed, not from a more powerful model.
Anthropic 公司通过其多智能体研究系统证明了这一点 。在该系统中,一个主控 Opus 4 智能体将子任务委派给 Sonnet 4 子智能体。尽管使用了相同的底层模型系列,该系统在研究任务上的性能比单个 Opus 4 智能体提高了 90.2%。所有性能提升都源于对上下文的管理方式,而非更强大的模型。
See the diagram below: 请看下图:
Tradeoffs 权衡取舍
These strategies are powerful, but they involve trade-offs with no universal right answers:
这些策略虽然有效,但都需要权衡取舍,没有放之四海而皆准的正确答案:
- Compression versus information loss: Every time you summarize, you risk losing a detail that turns out to matter later. The more aggressively you compress, the more you save on tokens, but the higher the chance of permanently destroying something important.
压缩与信息丢失: 每次做摘要,你都有可能丢掉某个事后看来很关键的细节。压缩越激进,节省的词元越多,但永久破坏重要信息的风险也越高。 - Single agent versus multi-agent: Anthropic’s multi-agent results are impressive, but others, notably Cognition, have argued that a single agent with good compression delivers more stability and lower cost. Both sides are debating the same core question of how to manage context effectively, and the answer depends on task complexity, cost tolerance, and reliability requirements.
单智能体与多智能体: Anthropic 的多智能体方案效果显著,但其他方案, 尤其是 Cognition ,则认为具有良好压缩性能的单智能体方案能够提供更高的稳定性和更低的成本。双方争论的核心问题是如何有效地管理上下文,而答案取决于任务的复杂性、成本承受能力和可靠性要求。 - Retrieval precision versus noise: RAG adds knowledge, but imprecise retrieval adds distractors. If the documents you retrieve aren’t genuinely relevant, they consume tokens and push important content into low-attention positions, so the retrieval system itself has to be well-engineered, or RAG makes things worse.
检索精度与噪声: RAG 能补充知识,但检索不准也会引入干扰项。如果取回的文档并不真正相关,它们会消耗词元,还会把重要内容挤到低注意力区域。因此检索系统本身必须设计得足够好,否则 RAG 反而会让效果变差。 - Cost versus richness: Every token costs money and processing time. The disproportionate scaling of attention means longer contexts get expensive fast, and context engineering is partly an economics problem of figuring out where the return on additional tokens stops being worth the cost.
成本与丰富度: 每个词元都要花钱,也都要花处理时间。注意力机制的非线性扩展意味着上下文一变长,成本就会上升得很快。所以上下文工程在某种程度上也是一个经济学问题:额外加入的词元,什么时候开始不再值得它带来的收益。
Conclusion 结论
The core takeaway is that the model is only as good as the context it receives. Working with LLMs effectively requires thinking about the entire system around the model, not just the model itself.
核心结论是:模型的效果,很大程度上取决于它收到的上下文。想把 LLM 用好,你必须思考模型周围的整个系统,而不仅仅是模型本身。
As models get more powerful, context engineering becomes more important. When the model is capable enough, most failures stop being intelligence failures and start being context failures, where the model could have gotten it right but didn’t have what it needed or had too much of what it didn’t need.
随着模型功能的日益强大,上下文工程变得愈发重要。当模型能力足够强大时,大多数失败不再是智能缺陷,而是上下文错误——模型原本可以做出正确的判断,但却缺少必要的信息,或者拥有了过多不必要的信息。
The strategies are evolving, and best practices are being revised as new models ship. However, the underlying constraints of finite attention, positional bias, and statelessness are architectural.
随着新模型的推出,策略不断演进,最佳实践也在不断修订。然而,有限注意力、位置偏好和无状态性等根本限制是架构层面的。
References 参考
- Attention Is All You Need
你只需要注意力 - Lost in the Middle: How Language Models Use Long Contexts
迷失在中间:语言模型如何使用长上下文 - Context Rot: How Increasing Input Tokens Impacts LLM Performance
上下文腐化:输入词元增加如何影响 LLM 性能 - Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
面向知识密集型自然语言处理任务的检索增强生成 - Context Engineering for Agents
面向智能体的上下文工程 - “Building Effective Agents
“构建高效智能体” - Post on context engineering by Andrej Karpathy
Andrej Karpathy 发表的关于上下文工程的文章