A Guide to AI Inference Engineering
Every time an LLM generates a response, two operations run in sequence on the same GPU. The first processes the input prompt and emits a single token. The second produces every token after that, one at a time.
每次 LLM 生成响应时,同一 GPU 上会依次运行两个操作。第一个操作处理输入提示,并生成一个词元。第二个操作再逐个生成后续词元。
From the outside, they look like stages of one process. However, inside the hardware, they have opposite bottlenecks. One is limited by raw compute. The other is limited by how fast data moves through memory. Most of the engineering work that makes production AI systems fast exists because of this split, and the techniques used to handle it are what inference engineering is built around.
从外部看,它们像同一流程的两个阶段。但在硬件内部,它们的瓶颈方向相反:一个受原始算力限制,另一个受数据通过内存移动的速度限制。生产 AI 系统的大部分性能工程都源于这个拆分,推理工程也围绕处理这个拆分展开。
Inference engineering is the discipline of running trained AI models in production efficiently. The work spans low-level GPU code, model serving frameworks, and the cloud infrastructure that ties them together. Engineers in this field optimize for some combination of latency, throughput, cost, and quality, with the specific mix depending on the product they support. A few years ago, this work happened almost entirely inside frontier AI labs. Today, it has become a broad specialty that any company running serious AI workloads invests in.
推理工程是在生产环境中高效运行已训练 AI 模型的学科。这项工作覆盖底层 GPU 代码、模型服务框架,以及连接它们的云基础设施。这个领域的工程师会根据产品需求,在延迟、吞吐量、成本和质量之间做组合优化。几年前,这项工作几乎只发生在前沿 AI 实验室内部。如今,它已经成为运行重要 AI 工作负载的公司会投入的通用专业方向。
In this article, we will walk through how inference works and why the field’s optimization techniques exist.
在本文中,我们将介绍推理的工作原理以及该领域优化技术存在的原因。
Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies.
免责声明:本文基于从各种来源公开共享的详细信息。如果您发现任何不准确之处,请评论。
The Rise of Inference Engineering
推理工程的兴起
Three years ago, inference engineering was a specialty practiced almost entirely inside frontier AI labs. The work concerned a small group of engineers building closed models that the rest of the industry consumed through APIs. That picture has shifted dramatically since 2024.
三年前,推理工程几乎完全是前沿 AI 实验室内部实践的专长。这项工作涉及一小群工程师构建封闭模型,而整个行业通过 API 消费这些模型。自 2024 年以来,这幅图景发生了巨大变化。
Open models drove the change. Hugging Face, the public registry for AI models, now hosts well over two million open models, roughly 25 times what existed five years ago. Open releases like DeepSeek V3 have closed the capability gap with closed models, giving companies a real choice between paying for a closed API and running an open model themselves.
开放模型推动了这一变革。作为 AI 模型的公共注册中心,Hugging Face 如今托管了超过两百万个开放模型,大约是五年前的 25 倍。像 DeepSeek V3 这样的开放模型发布已经缩小了与封闭模型的能力差距,为企业提供了在支付封闭 API 费用和自行运行开放模型之间的真实选择。
Self-hosting open models brings three operational advantages over closed APIs:
自行托管开放模型相较于封闭 API 有三个运营优势:
- Latency profiles can be tuned for the workload pattern of a specific product, where public APIs optimize for general throughput across many customers.
延迟表现可以根据特定产品的负载模式进行调整,而公共 API 通常面向许多客户的通用吞吐量优化。 - Uptime can reach four nines or better with dedicated deployments, comparing favorably to the two nines typical of public APIs.
专用部署可以让可用性达到四个 9 或更高,优于公共 API 常见的两个 9。 - Costs typically drop by around 80 percent at scale once volume justifies the engineering investment.
当调用量足以支撑工程投入后,规模化成本通常会下降约 80%。
The result is that companies across many categories now build serious inference stacks, including AI-native startups, established products integrating AI into existing workflows, and even traditionally cautious sectors like healthcare.
结果是,许多类型的公司都开始构建成熟的推理栈,包括 AI 原生初创公司、将 AI 集成到现有工作流的成熟产品,甚至医疗保健这类传统上较谨慎的行业。
Cursor offers a representative example. The team built Composer 2.0 on top of an open model, applying extensive inference engineering to deliver autocomplete latency below what closed APIs offer.
Cursor 提供了一个有代表性的例子。团队在开放模型之上构建了 Composer 2.0,通过大量推理工程投入,实现了低于封闭 API 的自动补全延迟。
The Two Phases of LLM inference
LLM 推理的两个阶段
Understanding why inference engineering looks the way it does starts with understanding what actually happens when a prompt arrives at an LLM. The process splits into two phases with very different physical demands on the GPU.
理解推理工程为何呈现当前形态,始于理解当提示到达大型语言模型(LLM)时实际发生的情况。该过程分为两个阶段,对 GPU 的物理需求差异很大。
A token is the atomic unit that an LLM works with. Roughly, it is a word or word fragment. The word “inference” might be one token, while “engineering” might break into two. Latency metrics that mention tokens per second are counted in this unit.
词元是 LLM 工作的基本单元。大致而言,它是一个单词或单词片段。英文单词 “inference” 可能是一个词元,而 “engineering” 可能拆成两个。每秒词元数这类延迟指标就是按这个单位计算的。
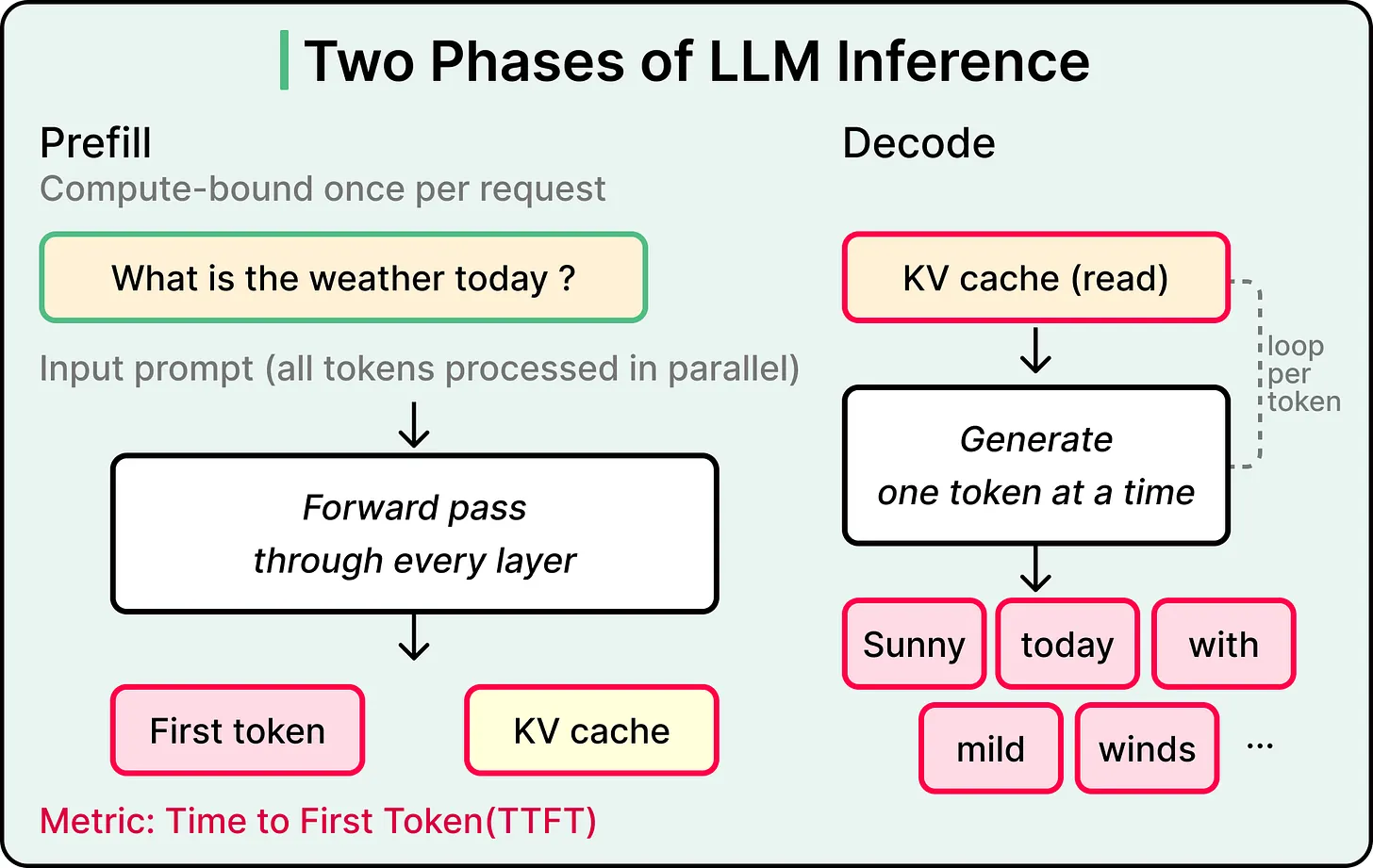
The first phase is called prefill.
第一阶段称为 prefill(预填充)。
The model takes the entire input prompt and runs it through every layer of weights in parallel. Two outputs come out of this burst, namely the first token of the response and the KV cache, which is a structure that stores intermediate values from the attention mechanism so they can be referenced as more tokens get generated.
模型将整个输入提示并行通过每一层权重。这次计算会产生两个输出:响应的第一个词元,以及 KV cache(KV 缓存)。KV cache 存储注意力机制的中间值,后续词元生成时可以继续引用。
Prefill is compute-bound. The GPU’s math units are the limiting factor because every input token gets processed simultaneously through every layer of the model, and throwing more raw computational power at this phase makes it faster. The metric that captures prefill performance is time to first token, or TTFT. That brief pause between sending a prompt to ChatGPT and seeing the first tokens appear is prefill in action.
Prefill(预填充)是计算受限(compute-bound)的阶段。GPU 的数学计算单元是瓶颈,因为每个输入词元会同时通过模型的每一层处理,在这个阶段投入更多原始算力可以加快速度。衡量 prefill 性能的指标是首次词元时间(Time to First Token, TTFT)。从发送提示到看到第一个词元出现之间的短暂停顿,就是 prefill 在起作用。
The second phase is the decode phase. The model generates each subsequent token one at a time, running a full forward pass through every layer of weights for every token. Each new token depends on every token before it, which makes the process fundamentally sequential, and the GPU does this thousands of times for a long response.
第二阶段是 decode(解码)阶段。模型逐个生成后续词元,并为每个词元通过所有层权重执行一次完整的前向传播。每个新词元都依赖于之前的所有词元,因此这个过程本质上是顺序的;对于长响应,GPU 会执行数千次这样的操作。
Decode is memory-bandwidth-bound. Math throughput sits mostly idle while the GPU spends its cycles reading model weights from memory for each forward pass, with the bottleneck living in data movement rather than arithmetic. The metric that captures decode performance is tokens per second, or TPS. The streaming pace of a long response is the decode phase at work.
Decode(解码)是内存带宽受限(memory-bandwidth-bound)的阶段。GPU 会在每次前向传播中从内存读取模型权重,数学吞吐量大多处于空闲状态,瓶颈在数据移动而非算术计算。衡量 decode 性能的指标是每秒词元数(Tokens Per Second, TPS)。长响应的流式输出速度,就是 decode 阶段的表现。
Since prefill and decode have opposite bottlenecks, a technique that accelerates one phase often has minimal impact on the other. This is why benchmarks report TTFT and TPS as separate numbers, with performance on each phase measured independently.
由于 prefill 和 decode 的瓶颈方向相反,加速其中一个阶段的技术通常只会给另一个阶段带来很小影响。因此,基准测试会把 TTFT 和 TPS 作为两个独立数字报告,并分别衡量两个阶段的性能。
This split is also the structural insight that organizes the rest of inference engineering. Once prefill and decode are understood as two distinct operations, the field’s techniques sort themselves into three groups: those that accelerate prefill, those that accelerate decode, and those that rebalance the two against each other.
这个拆分也是组织推理工程其余内容的结构性洞察。一旦把 prefill 和 decode 理解为两种不同操作,这个领域的技术就会自然分成三类:加速 prefill 的技术、加速 decode 的技术,以及在两者之间重新平衡系统的技术。
The picture above is somewhat simplified. Real inference engines run batching, scheduling, and other complexity layered on top, and the prefill-decode split holds underneath all of it, which is why it serves as the foundation for the rest of this article.
上图做了简化。真实推理引擎还会叠加 batching、scheduling 和其他复杂机制,但 prefill-decode 拆分位于这些机制的底层,因此它构成了本文后续内容的基础。
Optimization Techniques
优化技术
With the prefill-decode split in mind, the major techniques in inference engineering become much easier to organize. Each one accelerates a specific phase, attacks both for different reasons, or restructures the system around the split itself.
理解 prefill-decode 拆分之后,推理工程中的主要技术就更容易组织起来。每种技术要么加速某个特定阶段,要么出于不同原因同时影响两个阶段,要么围绕这个拆分重构系统。
Let us cover each of the six techniques in detail.
下面逐一介绍这六类技术。
Batching
批处理
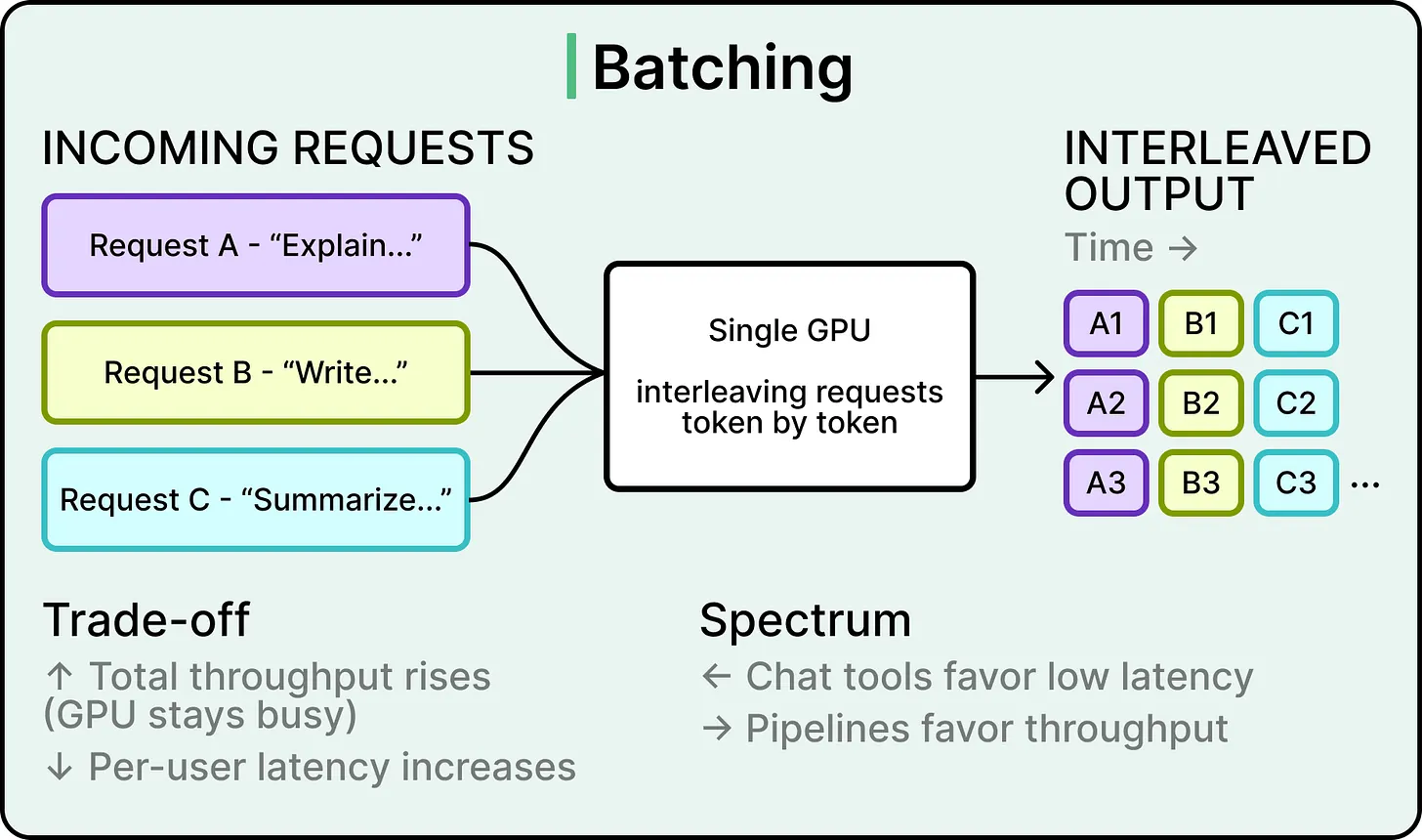
Batching is the most basic way to scale a single GPU’s output. The inference engine weaves multiple requests together, token by token, so one GPU can serve many users at once. Throughput rises significantly because the GPU’s compute capacity gets fully utilized instead of sitting idle between requests.
Batching(批处理)是扩展单块 GPU 输出能力的最基本方式。推理引擎会按词元把多个请求交织在一起,让一块 GPU 可以同时服务多个用户。GPU 计算能力被持续填满后,总吞吐量会显著提高。
The cost is paid in per-user latency.
代价体现在单个用户的延迟上。
A single user on an unbatched system gets the lowest possible response time, while the same user on a heavily batched system waits longer because the GPU is also serving other requests. This trade-off is the primary tension that every other technique navigates around, and different products land at different points on the spectrum, with consumer chat tools favoring lower latency and batch processing pipelines favoring higher throughput.
单请求系统可以给单个用户最低响应时间;高 batching 系统中,同一个用户需要等待 GPU 同时处理其他请求。这个取舍是其他技术都要围绕处理的主要张力,不同产品会落在不同位置:消费级聊天工具更偏低延迟,批处理管线更偏高吞吐量。
Prefix Caching
前缀缓存
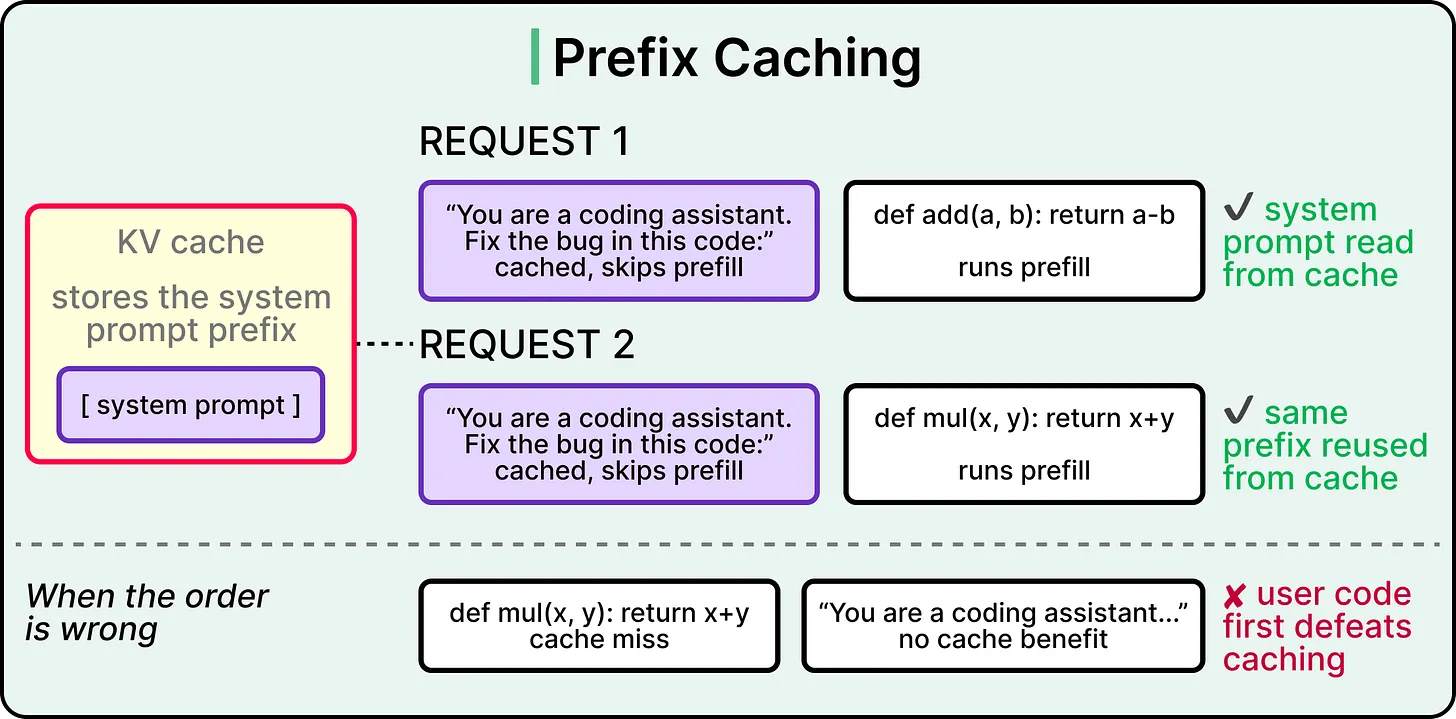
Prefix caching accelerates prefill by reusing KV cache values across requests. When two prompts share an opening segment, like a long system prompt that is identical across thousands of requests, the engine computes that prefix once and reads from cache thereafter. This is why API providers charge less for cached input tokens.
Prefix caching(前缀缓存)通过跨请求复用 KV cache 值来加速 prefill。当两个提示共享开头片段时,例如数千个请求中完全相同的一段长系统提示,引擎会先计算一次这个前缀,之后直接从缓存读取。这也是 API 提供商对 cached input tokens 收取更低费用的原因。
The catch is that the cache helps from the start of the sequence up to the first non-matching token. If the very first token differs between two prompts, prefix caching delivers zero savings even when the rest of the sequence is identical. Therefore, prompt structure has direct cost and latency implications, and putting variable user input late in the prompt while keeping shared content early gives the cache something to work with.
关键点在于,缓存只能从序列开头命中到第一个不匹配的词元。只要两个提示的第一个词元不同,即使后续序列完全相同,前缀缓存的节省量也为零。因此,提示结构会直接影响成本和延迟:把可变的用户输入放在提示后段,把共享内容保持在前段,可以让缓存发挥作用。
Quantization
量化
Quantization helps both phases of inference, though for different reasons.
Quantization(量化)可以帮助推理的两个阶段,但原因各有不同。
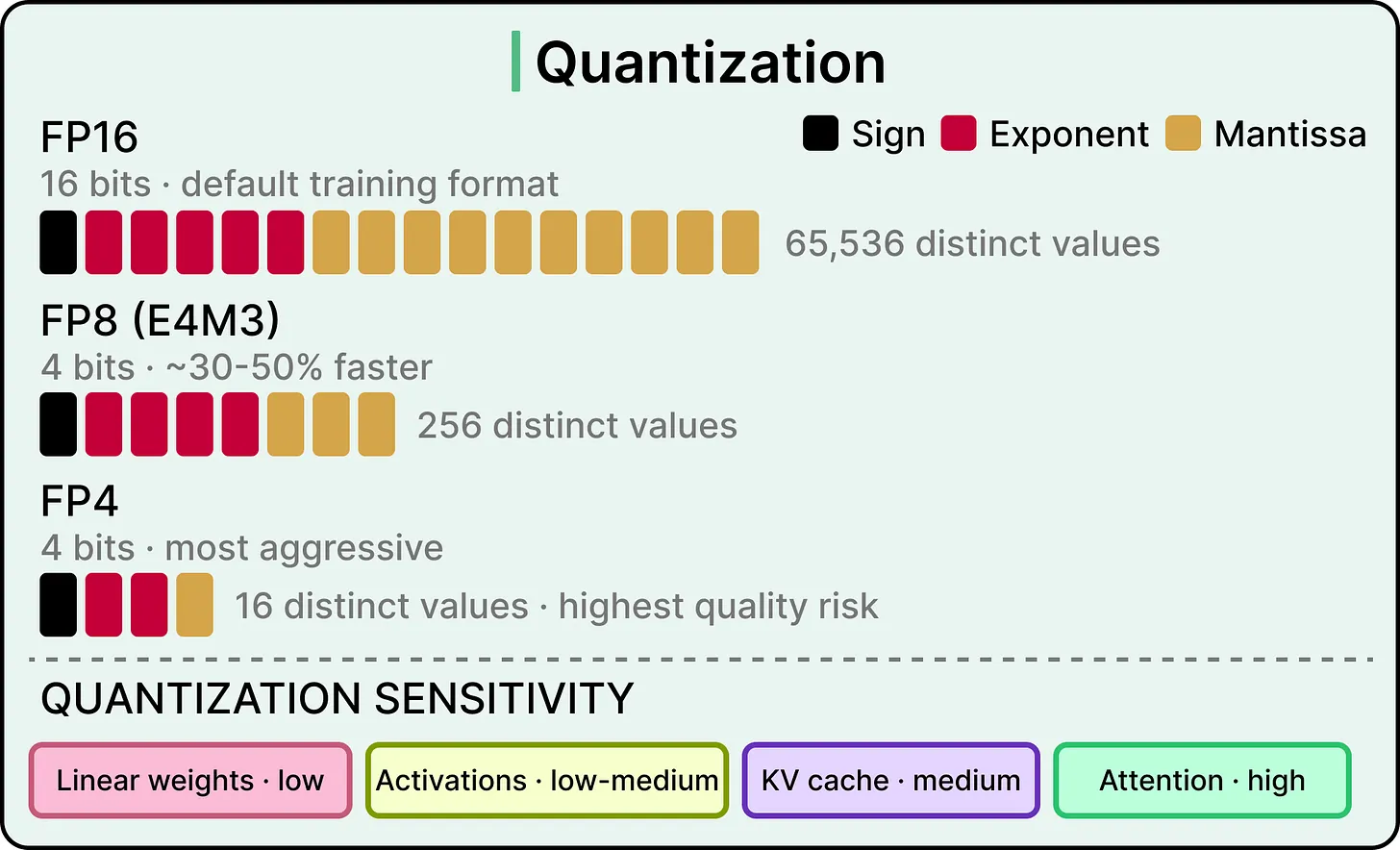
The basic move is storing model weights in a lower-precision number format. Most modern models train in 16-bit floating-point, and quantization compresses those values down to 8-bit or 4-bit representations, which means smaller weights occupying less memory and requiring less data movement.
它的基本做法是用更低精度的数字格式存储模型权重。大多数现代模型使用 16 位浮点数训练,量化会把这些值压缩成 8 位或 4 位表示,让权重更小、占用内存更少,并减少数据移动。
Prefill speeds up because lower-precision math operations run faster on the specialized math units inside modern GPUs. Decode speeds up because reduced memory bandwidth pressure means weights are loaded from memory more quickly per forward pass. A typical step down in precision yields roughly 30 to 50 percent better performance, with the exact gain depending on the model and the technique applied.
Prefill 会变快,因为低精度数学运算在现代 GPU 的专用数学单元上运行更快。Decode 也会变快,因为内存带宽压力降低后,每次前向传播从内存加载权重的速度更快。典型的精度下调大约能带来 30% 到 50% 的性能提升,具体收益取决于模型和所用技术。
The cost is potential quality degradation, and different parts of a model tolerate quantization differently.
代价是质量可能下降,而且模型不同部分对量化的容忍度不同。
Linear weights handle it well, activations are somewhat more sensitive, the KV cache is more sensitive still, and attention layers are the most sensitive of all. The reason is that small precision errors in attention layers compound across the sequence of tokens, with each token’s calculation building on the previous ones, so even small errors snowball into meaningful quality loss over a long response.
线性权重通常很适合量化,activations 稍微敏感,KV cache 更敏感,attention layers 最敏感。原因是注意力层中的小精度误差会沿词元序列累积,每个词元的计算都建立在前面词元之上,因此长响应里很小的误差也可能滚雪球成明显的质量损失。
Most production setups leave attention at full precision for this reason. The bulk of the engineering work in quantization comes down to figuring out which parts to compress and how aggressively.
因此,大多数生产环境会让 attention 保持全精度。量化的大部分工程工作,本质上是判断哪些部分可以压缩,以及压缩到什么程度。
Speculative Decoding
推测式解码
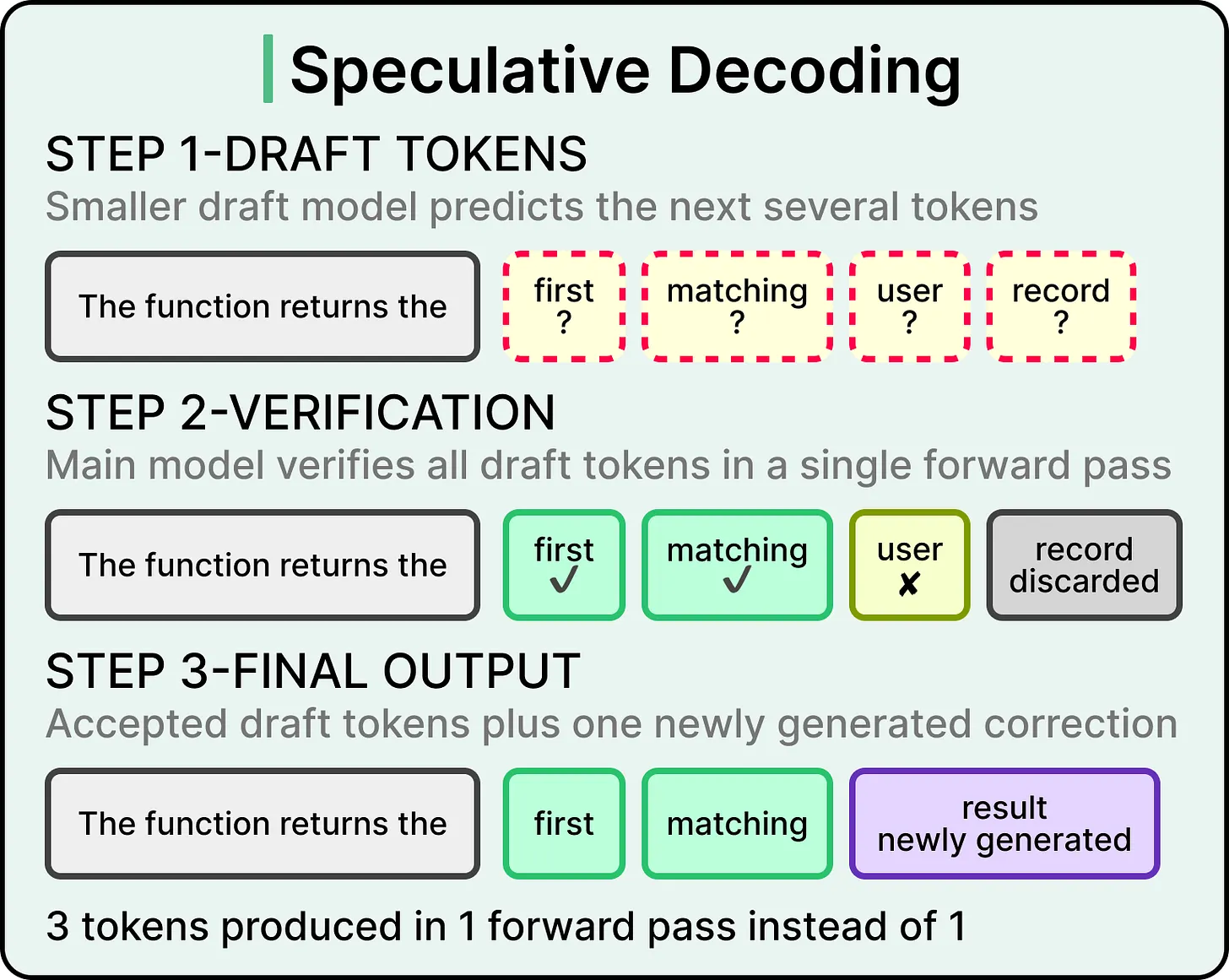
Speculative decoding accelerates the decode process by exploiting an asymmetry. Generating a token from scratch is expensive, while verifying whether a candidate token matches what the main model would produce is much cheaper. The Sudoku analogy works here, where solving the puzzle takes effort, while checking a finished puzzle is fast.
Speculative decoding(推测式解码)利用一种不对称性来加速 decode 过程:从零生成一个词元很昂贵,验证一个候选词元是否匹配主模型会生成的内容则便宜得多。这里可以类比数独:解题需要投入 effort,检查已经填好的答案很快。
In speculative decoding, a smaller draft model predicts the next several tokens, and the main model verifies all of them in a single forward pass, accepting the ones that match its own predictions and rejecting the rest. The result is multiple tokens emerging per forward pass through the main model, where one would normally appear.
在推测式解码中,一个较小的 draft model 会预测接下来的多个词元,主模型再用一次前向传播验证这些候选词元,接受与自己预测匹配的候选,丢弃其余候选。结果是主模型每次前向传播可以产出多个词元,而常规流程通常只产出一个。
Speculative decoding improves TPS while leaving TTFT unchanged, because prefill still runs normally. The technique also works best at smaller batch sizes, when the GPU has spare compute capacity to spend on verification. At larger batch sizes, when many requests are being served at once, the GPU is already saturated, and speculation gets dynamically disabled because every cycle is needed for the main workload.
推测式解码会提高 TPS,同时让 TTFT 维持原值,因为 prefill 仍然正常运行。这项技术也最适合较小 batch size,此时 GPU 有空余算力可用于验证。batch size 较大、系统同时服务许多请求时,GPU 已经饱和,每个周期都要用于主工作负载,speculation 会被动态关闭。
Parallelism
并行
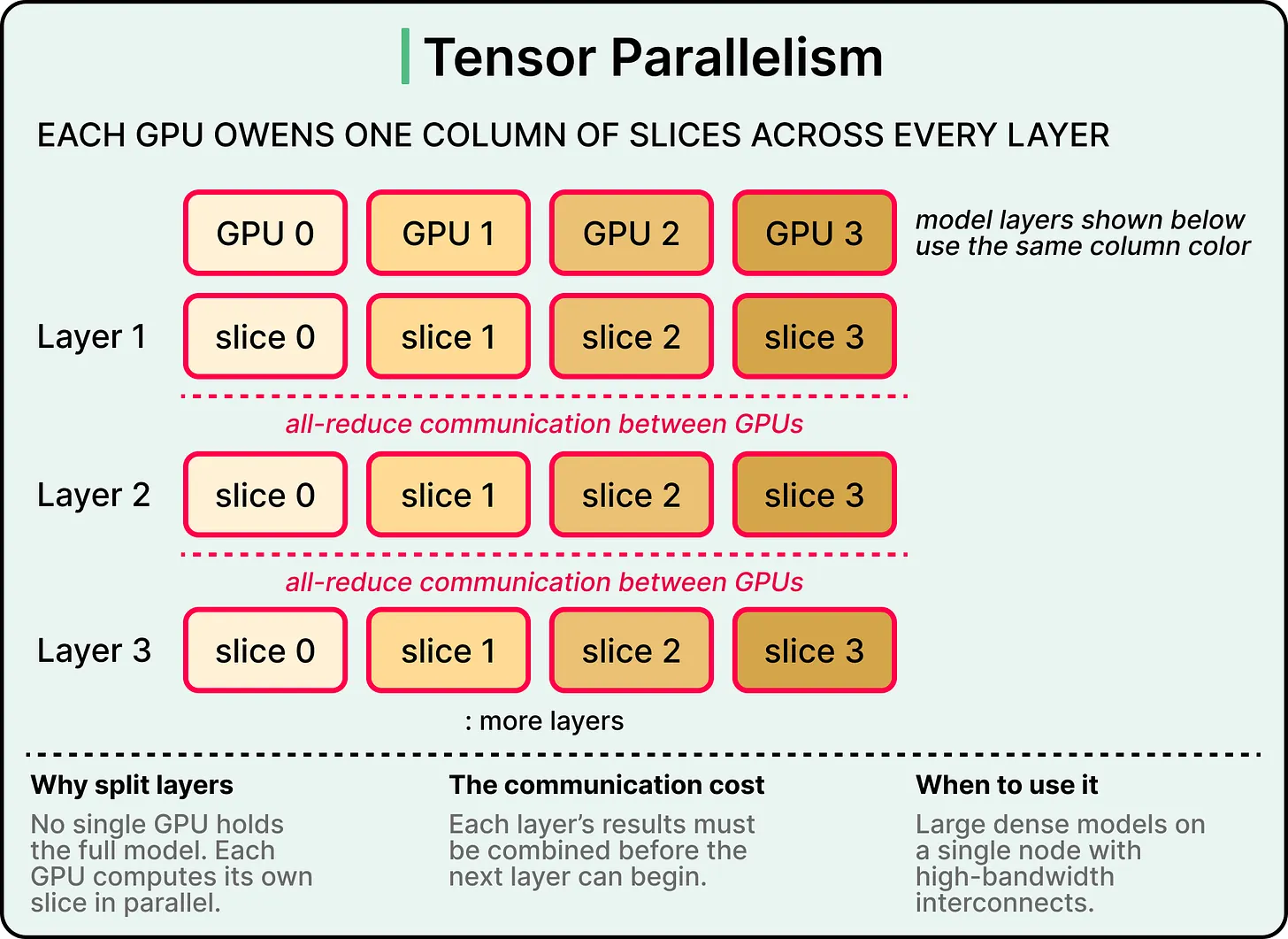
Parallelism techniques let large models run across multiple GPUs when a single one falls short, either because the model is too big to fit in memory or because single-GPU latency is too high. Two main approaches dominate the open model landscape: tensor parallelism and expert parallelism.
Parallelism(并行)技术让大模型可以跨多块 GPU 运行,适用于模型太大、单块 GPU 内存放不下,或单 GPU 延迟过高的情况。开放模型领域主要有两种方法:tensor parallelism 和 expert parallelism。
Tensor parallelism splits each layer of the model across multiple GPUs. Every GPU holds a fragment of every layer, and the GPUs share the work for each forward pass. This requires high-bandwidth interconnects between the GPUs, like NVIDIA’s NVLink, because results need to be combined after every layer. Tensor parallelism is the default choice for serving very large dense models, where the bandwidth-hungry communication is offset by the speedup from sharing per-layer work.
Tensor parallelism(张量并行)会把模型的每一层拆到多块 GPU 上。每块 GPU 都持有每一层的一部分,并共同完成每次前向传播。由于每层之后都需要合并结果,这种方式要求 GPU 之间有高带宽互连,例如 NVIDIA NVLink。服务超大 dense model 时,tensor parallelism 是默认选择,因为拆分每层工作带来的速度提升可以抵消高带宽通信成本。
Expert parallelism applies specifically to mixture-of-experts models, where only a subset of the model’s parameters activate for each token. Different experts get distributed across different GPUs, and tokens get routed to whichever experts they need. The communication overhead is lower than tensor parallelism because experts operate independently, which makes expert parallelism well-suited for multi-node deployments where bandwidth is more limited. Most production deployments combine both, using tensor parallelism within a node and expert parallelism across nodes.
Expert parallelism(专家并行)专门用于 mixture-of-experts models。MoE 模型中,每个词元只会激活模型参数的一部分。不同 experts 会分布到不同 GPU 上,词元会被路由到自己需要的 experts。由于 experts 独立运行,通信开销低于 tensor parallelism,因此 expert parallelism 很适合带宽更受限的多节点部署。多数生产部署会组合两者:节点内使用 tensor parallelism,节点间使用 expert parallelism。
Disaggregation
解耦
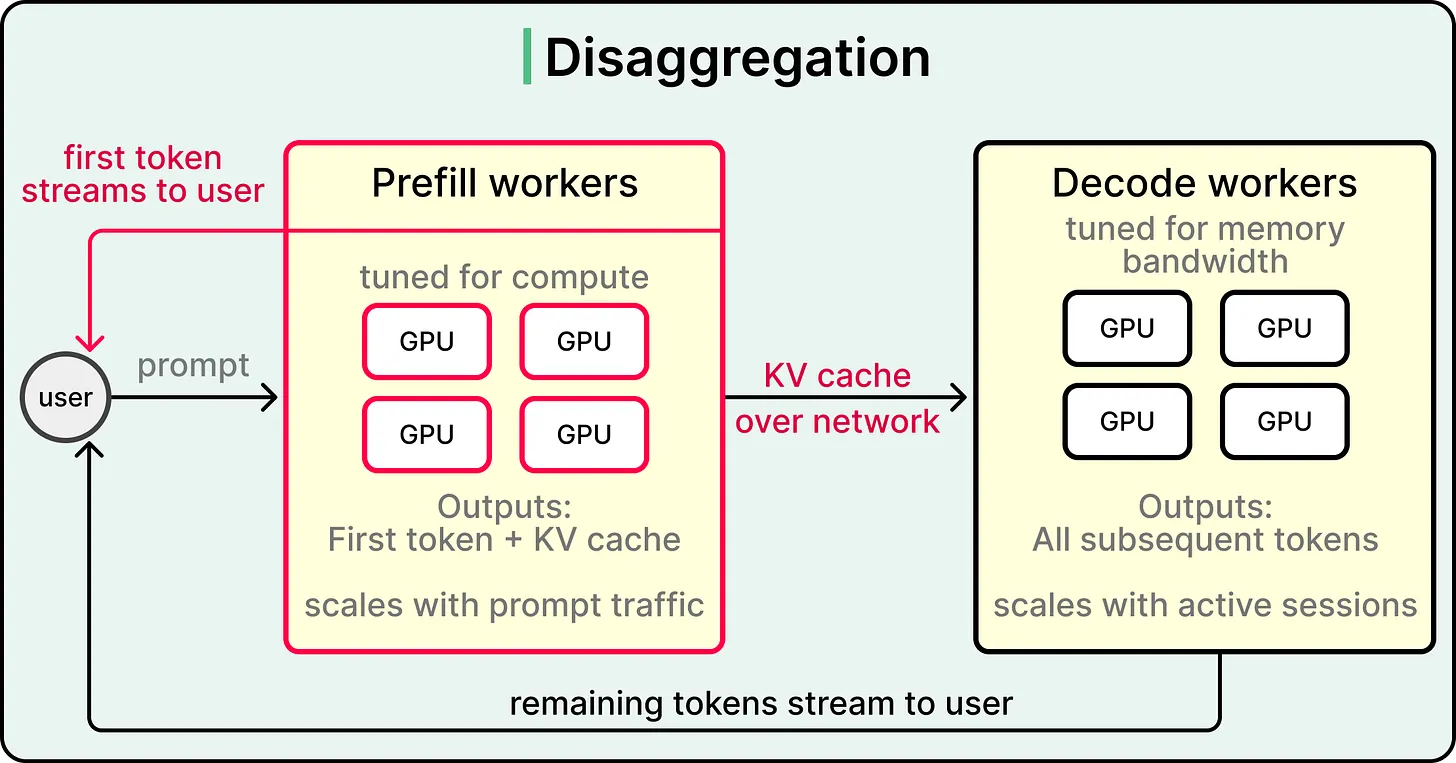
Disaggregation takes the prefill-decode split literally. The idea is to run prefill on one set of GPUs and decode on another, with the KV cache shipped between them over the network. Each set uses hardware tuned to its specific bottleneck, and each set scales independently based on its own traffic pattern.
Disaggregation(解耦)把 prefill-decode 拆分直接落实到架构里。它的思路是在一组 GPU 上运行 prefill,在另一组 GPU 上运行 decode,并通过网络在两者之间传输 KV cache。每组 GPU 都使用适合自身瓶颈的硬件,并根据各自流量模式独立扩展。
The flow becomes a three-step process:
流程变成三步:
- The prefill engine takes the input sequence and produces both the first token and the KV cache.
prefill engine 接收输入序列,生成第一个词元和 KV cache。 - The cache gets sent over a fast interconnect to the decode engine, and the decode engine handles every subsequent token.
cache 通过高速互连发送给 decode engine,再由 decode engine 处理每个后续词元。 - In conditional disaggregation, short or already-cached requests skip the handoff entirely and run on the decode engine alone, which performs better against real-world traffic that includes a mix of long and short prompts.
在 conditional disaggregation(条件式解耦)中,短请求或已经命中缓存的请求会跳过交接流程,直接在 decode engine 上运行。真实流量通常混合了长提示和短提示,这种方式表现更好。
Disaggregation is the most architectural of the techniques covered here. It treats prefill and decode as separate services with separate operational concerns, giving operators independent levers to scale each one. Companies running large-scale inference often consider this a near-mandatory step once their workload mix is well understood.
在本文覆盖的技术里,disaggregation 最偏架构层。它把 prefill 和 decode 当作具有不同运营关注点的独立服务,让运营者可以分别扩展每一部分。运行大规模推理的公司一旦充分理解自己的工作负载组合,通常会把它视为接近必选的步骤。
When to Invest in Inference Engineering
何时投资推理工程
Putting these techniques into production is a serious task, and combining them adds further complexity. The question every engineering team has to answer is whether to take on this work or whether off-the-shelf APIs are still the right choice. The answer depends on the stage of the product.
把这些技术投入生产是一项严肃工程,组合使用还会进一步增加复杂度。每个工程团队都要回答一个问题:当前阶段应该承担这项工作,还是继续使用现成 API。答案取决于产品阶段。
Early in building an AI product, off-the-shelf APIs from established providers are almost always the right choice. Meaningful optimization requires real constraints to work against, and early-stage products tend to have fuzzy assumptions about traffic patterns, latency requirements, and unit economics. Engineering effort at this stage is better spent shipping product, since the complexity of running a custom inference stack slows down iteration when iteration speed is what actually matters.
在 AI 产品早期,成熟供应商的现成 API 通常是合适选择。有意义的优化需要真实约束,而早期产品对流量模式、延迟要求和单位经济性的假设往往还很模糊。这个阶段的工程精力更适合用于发布产品,因为自定义推理栈的复杂度会拖慢迭代,而此时真正重要的是迭代速度。
Three signals usually indicate the equation has shifted:
通常有三个信号表示局面已经变化:
- API costs have grown into a meaningful expense line.
API 成本已经增长成一项重要支出。 - Latency requirements have moved past what closed APIs can deliver.
延迟要求已经超过封闭 API 的交付能力。 - Reliability needs have started to exceed what vendor SLAs offer.
可靠性需求已经开始超过供应商 SLA 提供的范围。
Cursor handled this transition well. Sub-second autocomplete latency was the product itself, and closed APIs aim for general throughput across many customers, while a code completion model demands a specific shape of speed. Self-hosting an open model and applying inference engineering across the stack made the latency target reachable, and the investment paid back because the constraints were real and the workload was well understood.
Cursor 很好地处理了这个转变。亚秒级自动补全延迟本身就是产品体验;封闭 API 面向多客户的通用吞吐量优化,代码补全模型需要特定形态的速度。自托管开放模型,并在整个栈上应用推理工程,让这个延迟目标变得可达;由于约束真实、工作负载被充分理解,这项投资获得了回报。
Conclusion
结论
LLM inference is two operations with opposite physical constraints.
LLM 推理包含两个物理约束相反的操作。
Prefill is compute-bound and runs once per request. Decode is memory-bandwidth-bound and runs once per token. Most of the techniques in inference engineering exist because of this split, and grasping it makes the rest of the field much easier to navigate.
Prefill 受计算限制,每个请求运行一次。Decode 受内存带宽限制,每个词元运行一次。推理工程中的大多数技术都源于这个拆分,理解它会让整个领域更容易把握。
Each technique covered above fits into the prefill-decode framework:
上面介绍的每种技术都可以放进 prefill-decode 框架:
- Batching trades per-user latency for total throughput.
Batching 用单用户延迟换取总体吞吐量。 - Prefix caching cuts prefill work when prompts share opening segments.
Prefix caching 在提示共享开头片段时减少 prefill 工作。 - Quantization compresses model weights to help both phases.
Quantization 通过压缩模型权重帮助两个阶段。 - Speculative decoding squeezes more tokens out of decode by exploiting idle compute.
Speculative decoding 利用空闲算力,从 decode 中产出更多词元。 - Parallelism scales models across multiple GPUs.
Parallelism 将模型扩展到多块 GPU。 - Disaggregation runs prefill and decode on separate hardware altogether.
Disaggregation 让 prefill 和 decode 分别运行在独立硬件上。
Layered on top of all this is the build-versus-buy question. Off-the-shelf APIs remain the right choice for most products in their early stages, while self-hosting starts to make sense when API costs grow into a real expense line, when latency requirements outgrow what closed APIs can deliver, or when reliability needs exceed vendor SLAs.
在这些技术之上,还有 build-versus-buy(自建还是购买)问题。对大多数早期产品来说,现成 API 仍然是合适选择;当 API 成本增长成真实费用项、延迟要求超过封闭 API 的交付能力,或可靠性需求超过供应商 SLA 时,自托管开始变得有意义。
References:
参考文献:
- Hugging Face Hub Documentation
Hugging Face Hub 文档 - DeepSeek-V3 Technical Report
DeepSeek-V3 技术报告 - Cursor — Composer: Building a fast frontier model with RL
Cursor — Composer:使用 RL 构建快速前沿模型 - Cursor — Introducing Composer 2
Cursor — 介绍 Composer 2 - DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
DistServe:面向 goodput 优化的大语言模型服务,将 prefill 和 decoding 解耦 - Efficient Memory Management for Large Language Model Serving with PagedAttention
使用 PagedAttention 为大语言模型服务实现高效内存管理 - Anthropic — Prompt Caching Documentation
Anthropic — 提示缓存文档 - NVIDIA TensorRT Documentation
NVIDIA TensorRT 文档 - Fast Inference from Transformers via Speculative Decoding
通过推测式解码实现 Transformer 快速推理 - Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Megatron-LM:使用模型并行训练数十亿参数语言模型 - NVIDIA Megatron-Core Developer Guide — Tensor Parallel
NVIDIA Megatron-Core 开发者指南 — 张量并行 - Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
超大规模神经网络:稀疏门控 Mixture-of-Experts 层 - NVIDIA NVLink and NVLink Switch
NVIDIA NVLink 和 NVLink Switch - Anthropic Claude API Documentation
Anthropic Claude API 文档